今日も見に来て下さって、ありがとうございます。地道ながらに更新を続けたせいか、コロナウィルスで引きこもり中の余裕のある人たちのおかげか、週間のユーザ数が三桁に達するようになってまいりました。以前書いた「Pythonでプログラミング キー入力を受け付ける」のアクセス数がなぜか多いので、調子にのってGUI版を書いてみることにしました。
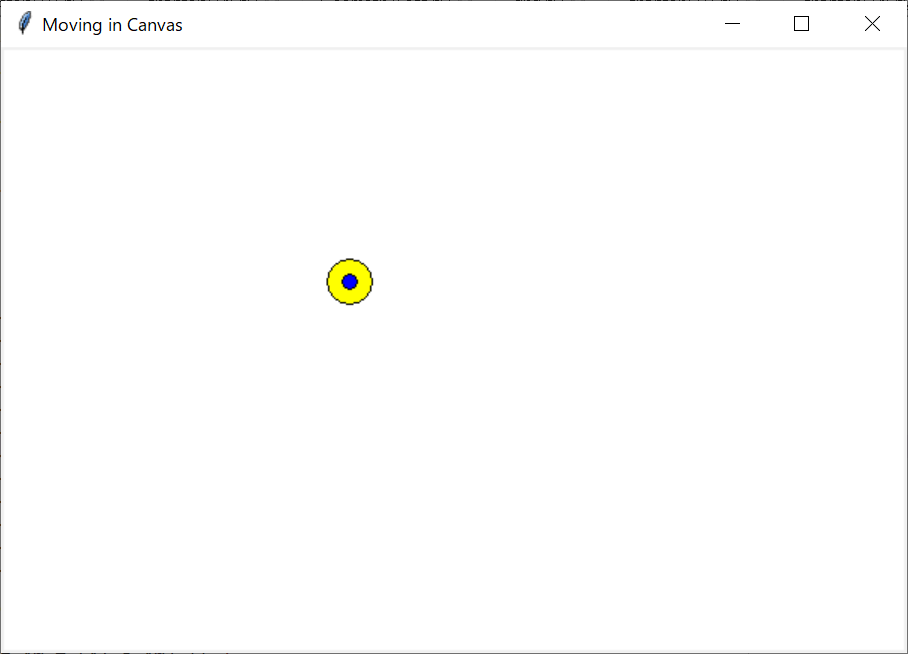
出来上がりイメージ
出来上がりイメージです。ウィンドウの中にキャンバスをつくって、その中に黄色い丸と青い丸を書きました。マウスを動かすと、丸がついて回ります。そして、矢印キーを押すと、キーを押した方向へ丸が移動します。という、単純なものです。
出来上がりソースコード
とりあえず、動かしてみたいんじゃ、という忙しい方のために、まずはソースを貼っておきます。
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Moving in Canvas")
self.pos = (0,0)
self.pressed = {}
self.canvas = tk.Canvas(width=600, height=400, background="white")
self.canvas.pack()
self.item = self.canvas.create_oval(10, 10, 40, 40, fill="yellow", tag="t")
self.inner_item = self.canvas.create_oval(20, 20, 30, 30, fill="blue", tag="t")
self.canvas.bind("<Motion>",self.move_by_mouse)
self.bind("<KeyPress>",self.key_pressed)
self.bind("<KeyRelease>",self.key_released)
self.move_by_key()
def move_by_mouse(self, event):
if self.pos == (0,0):
x0, y0, x1, y1 = self.canvas.coords(self.item)
px = x0 + (x1 - x0) // 2
py = y0 + (y1 - y0) // 2
dx = event.x - px
dy = event.y - py
self.canvas.move("t", dx, dy)
self.pos = (event.x, event.y)
return
dx = event.x - self.pos[0]
dy = event.y - self.pos[1]
self.pos = (event.x, event.y)
self.canvas.move("t", dx, dy)
def key_pressed(self, event):
self.pressed[event.keysym] = True
self.pos = (0,0)
def key_released(self, event):
self.pressed.pop(event.keysym, None)
def move_by_key(self):
dx, dy = 0, 0
m = 5
if "Up" in self.pressed:
dy -= m
if "Down" in self.pressed:
dy += m
if "Left" in self.pressed:
dx -= m
if "Right" in self.pressed:
dx += m
x0, y0, x1, y1 = self.canvas.coords(self.item)
px = x0 + (x1 - x0) // 2 + dx
py = y0 + (y1 - y0) // 2 + dy
if 0 <= px <= self.canvas.winfo_width() and 0 <= py <= self.canvas.winfo_height():
self.canvas.move("t", dx, dy)
self.after(10, self.move_by_key)
if __name__ == '__main__':
app = App()
app.mainloop()
内容説明
まずは、1行目、「import tkinter as tk」で、tkinterモジュールをインポートします。「as tk」と指定してあるのは、グローバルな名前空間が汚されないようにするためです。チュートリアルでありがちな、「from tkinter import *」はダメな例なのでまねしないようにしましょう。
次に、3行目、「class App(tk.Tk):」GUIアプリケーションのトップレベルは、必ずtk.Tkになりますので、これを継承してアプリケーションを作成します。
4、5行目「def __init__(self):」では、アプリケーションの初期化を行います。まずは、親のメソッドを呼び出すため、「super().__init__()」をコールしています。ここまでは、もうお約束ですので完全に記憶しましょう。
6行目「self.title("Moving in Canvas")」ウィンドウのタイトルをセットしています。tkinterでは特に何も意識せず日本語も使えます。
7、8行目は、あとで使う変数を初期化しています。
9~12行目で、Canvasをつくって、その上に丸を書いています。ポイントは、この丸を書くときに「tag="t"」とタグをセットしているところでしょうか。あとで出てきますが、キャンバス上のモノは、IDかタグで動かしたり属性を変更したりすることができます。IDだと一つしか動かせませんので、今回は二つの丸を動かすために、タグを指定しました。
13~15行目は、イベントにバインドしています。どういうことかというと、例えばこの「self.canvas.bind("<Motion>",self.move_by_mouse)」の場合だと、self.canvasで<Motion>(マウスポインタがキャンバスで動いた!)というイベントが発生したときには「self.move_by_mouse」を呼び出してね、と、割り当てている、ということになります。日本語のニュアンスだと結び付けている、というのが適当でしょうか。
ここでは、3つのイベントをそれぞれ割り当てています。
- <Motion> マウスが動いた → self.move_by_mouse
- <KeyPress> キーが押された → self.key_pressed
- <KeyRelease> キーが離された → self.key_released
マウスによる移動と、キー入力による移動はそれぞれ独立しています。まずはマウスによる移動の方から説明します。
マウスによる移動
マウスが動くたびに、<Motion>イベントが発生します。14行目でバインドしたので、マウスの動きに合わせてself.move_by_mouseが呼び出されます。マウスに合わせて動作させるのは、これだけで充分です。ポイントは、self.canvas.moveで指定できるのは、指定したタグを移動するオフセット値になることです。現在位置からx軸に+10、y軸にー20といった風に設定することになります。eventで取得できるのが左上のコーナーを0,0との基準にしてプラスに増えていく座標になっています。このため、最初の動き出しの時だけは、動かずに動作開始点を保持するだけにして、次のイベントが発生したときに、前の位置から5,3動く、といった指定になるようにしました。
ちなみに、x0, y0, x1, y1 = self.canvas.coords(self.item)は、self.itemの左上の原点からの座標を取得するメソッドです。self.itemを矩形で切り取って左上の座標と右下の座標を同時に取得しています。self.itemの中心座標を計算するのに、px = x0 + (x1 - x0) // 2とpy = y0 + (y1 - y0) // 2としています。その後、dx = event.x - pxとdy = event.y - pyにて、中心点からマウスカーソルの座標までのそれぞれの移動距離を計算しています。その後、self.canvas.move("t", dx, dy)として、マウスカーソルまでself.itemを移動します。
キーによる移動
キーが押されるたびに、<KeyPress>イベントが発生します。押したキーを話すたびに、<KeyRelease>イベントが発生します。イベントにはそれぞれ、key_pressed、key_releasedがバインドされていました。このため、キーが押されると、8行目で初期化されたディクショナリ「self.pressed = {}」の中に、押されたキーのシンボルがTrueとして登録されます。例えば、右キーを押すと、ディクショナリの中身は{'Right': True}という風になります。キーは同時に押すこともできますので、例えば上と右キーを同時に入力するとディクショナリの中身は{'Up': True, 'Right': True}のようになります。ソースコードを見ればわかると思いますが、キーのシンボルはevent.keysymで取得しています。
初期化の説明の時にはさらりと飛ばしましたが、初期化(__init__(self))の最後の行、16行目で、self.move_by_key()を呼び出しています。このmove_by_keyは呼び出されると、最後にself.after(10, self.move_by_key)を呼び出すことで、自分自身を10ミリ秒後に呼び出すことで、無限ループを開始します。このループにて、キー入力を処理しています。
具体的には、キー入力で上下左右の移動距離(ここでは5)をセットして、キャンバスのmoveメソッドを呼び出すself.canvas.move("t", dx, dy)ことでアイテムを動かしています。その直前のif文は、画面の外へはみ出して移動しないように制御しています。
まとめ
上記のキー入力制御のアプローチは、個別にイベントをバインドするやりかたよりも好ましいと思います。個別にバインドした場合は、キー入力しない限りイベントが発生しないので、位置を飛ばして移動するような移動には使えますが、よりスムーズな移動には今回のようなイベントループで制御する必要があります。
これでtkinterを使うときにキー入力やマウスによるイベントの制御はバッチリですね!