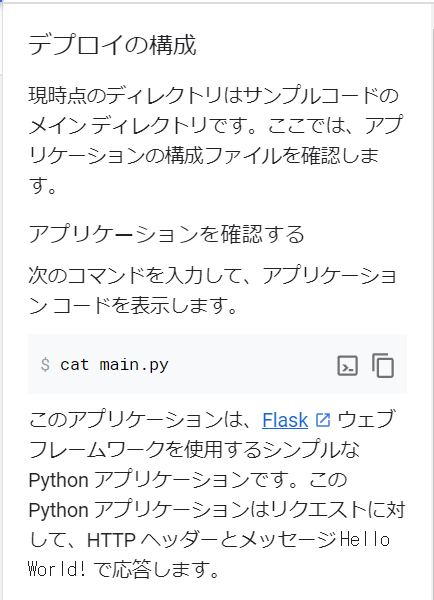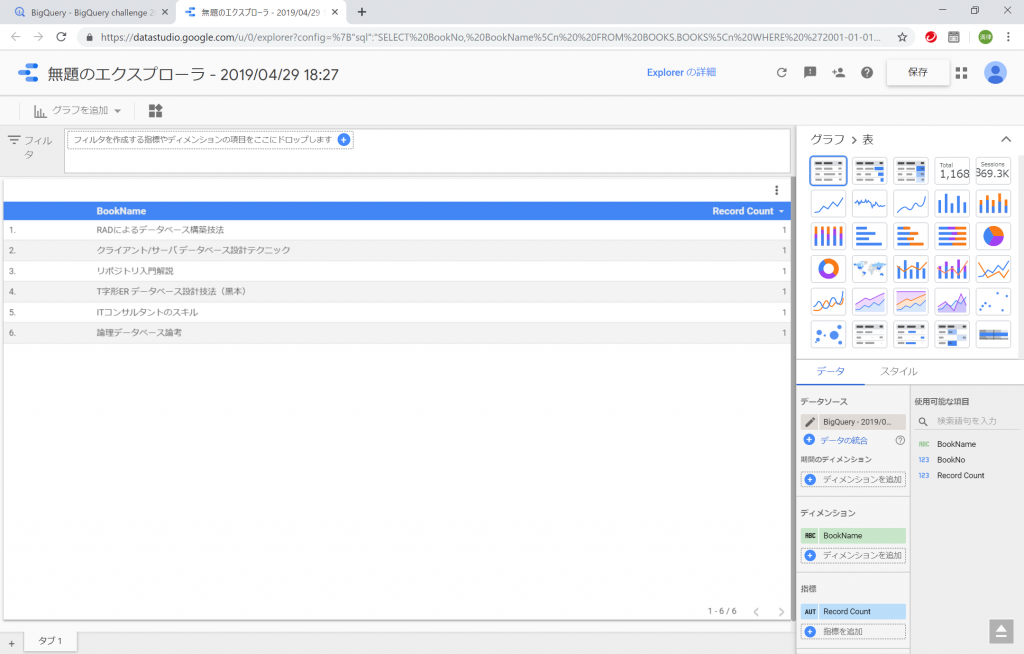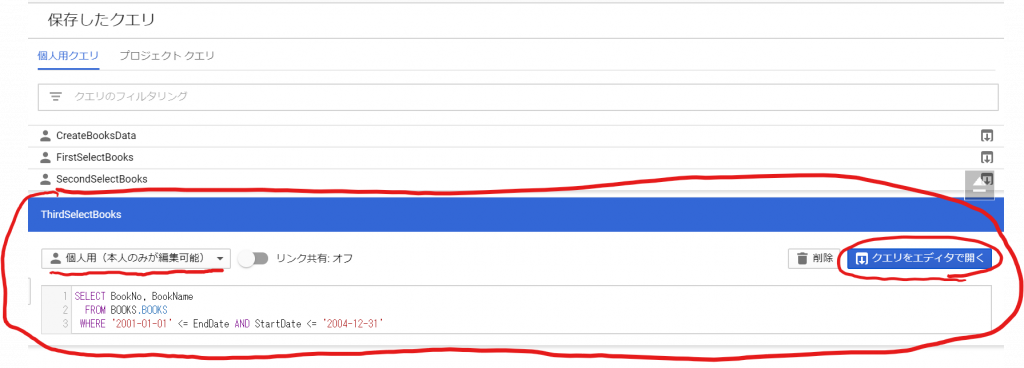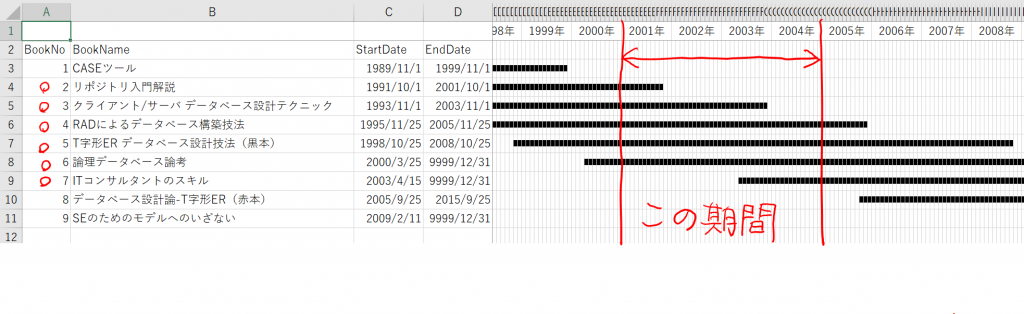
今日も見に来てくださって、ありがとうございます。石川さんです。今夜は中秋の名月です。と言っても書き始めたのが遅いし、記事も長くなりそうなので、書き終わって公開するときには、中秋の名月は終わっているでしょうね。
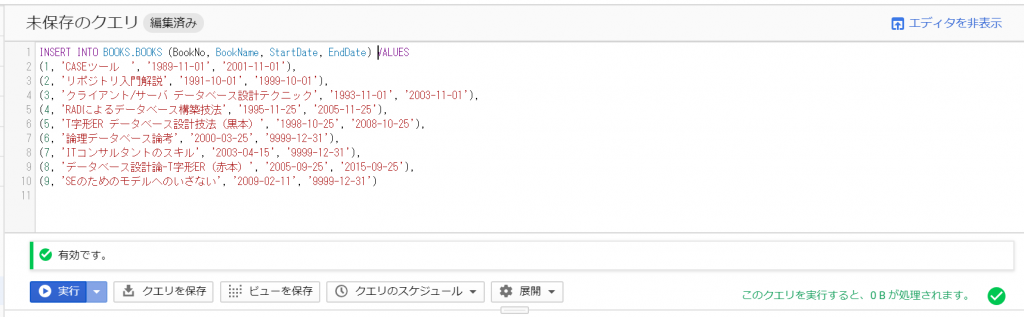
さて、今回は、ちょっと要望がありまして、GCPのCloud SQLを使ってみることにしました。ぼくはOracleマスターということもあり、普段データベースを使うと言えば、Oracleを使っています。そう、RDBMSシェアNo1のオラクルさまです。ただ、GCPではOracleのインスタンスが作れるようになっていないのですよね。Oracleもクラウドサービスを展開していますから、ライバル関係ということになるのかなぁ。そんなこともあり、GCPのCloud SQLのラインナップには登場しそうにありませんよね。
所有している書籍やWeb上のGCPのドキュメントを色々と読んで、バッチリ理解してから始めようと思っていたのですが、いつまでたっても一向に始められません。こういう時は、まずやってみる、ということが大切ですよね。ということで、スクリーンショットを取りながら進めてみたいと思います。
新規プロジェクトの作成
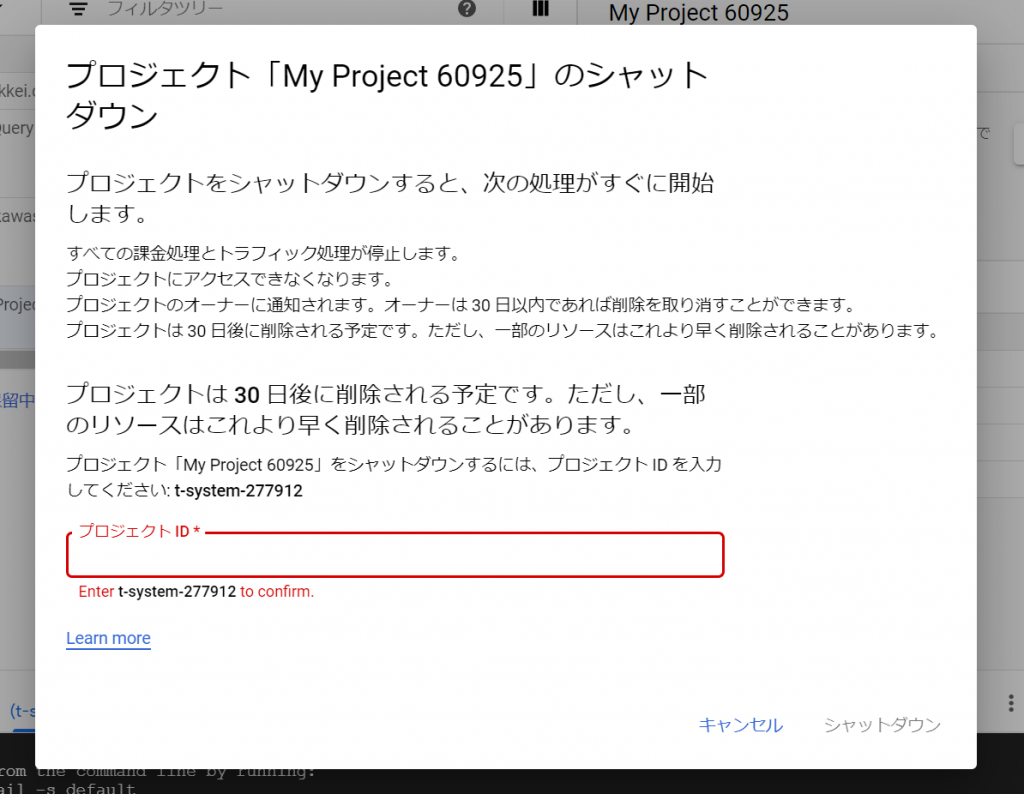
では、まずはGCPコンソールへ行って、プロジェクトを作成しましょう。三角形をクリックします。

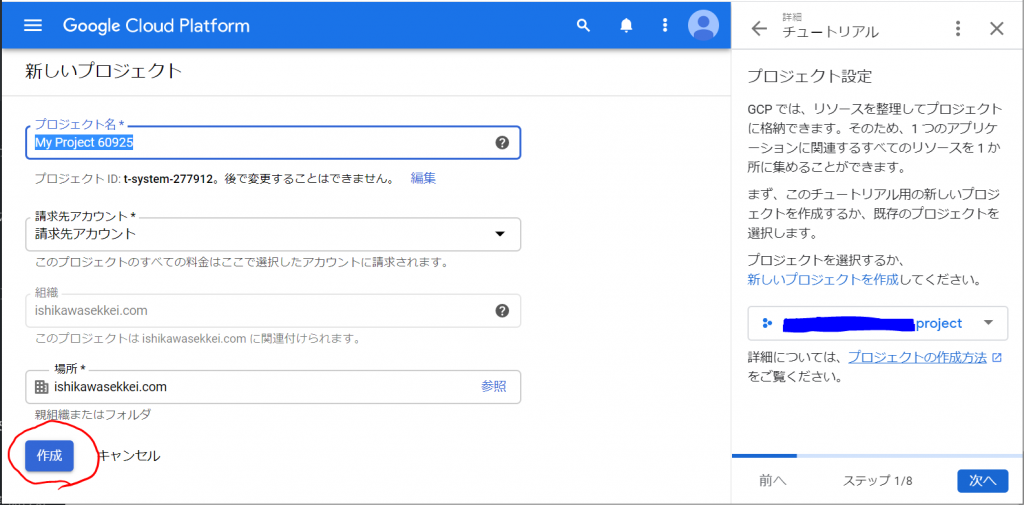
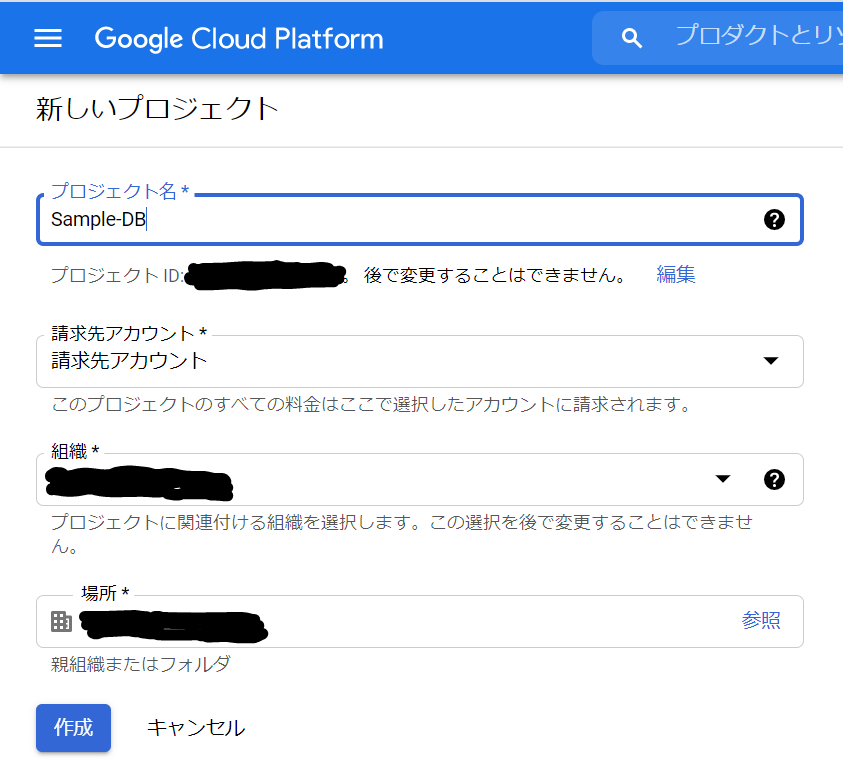
今回は、プロジェクト名を「Sample-DB」にしてみます。上記の三角形をクリックすると以下のようなウィンドウが表示されなりますので、「新しいプロジェクト」をクリックします。
プロジェクト名は、「Sample-DB」に入力しなおして、あとはデフォルトのまま「作成」ボタンをクリックします。
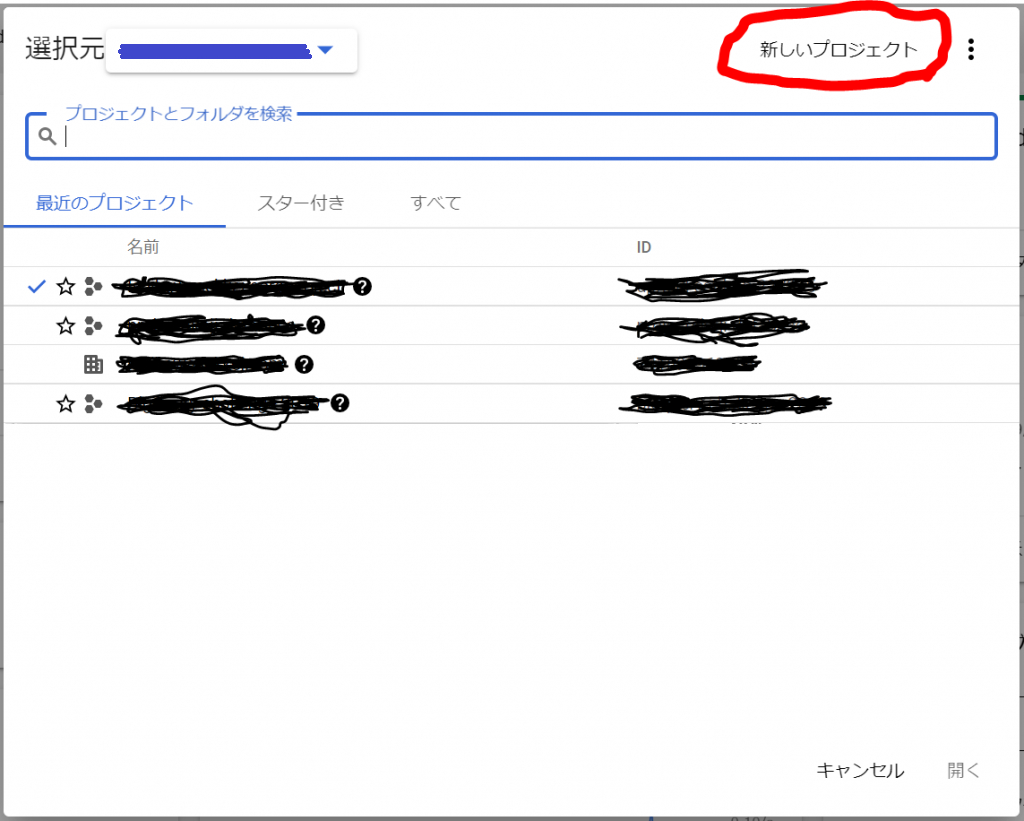
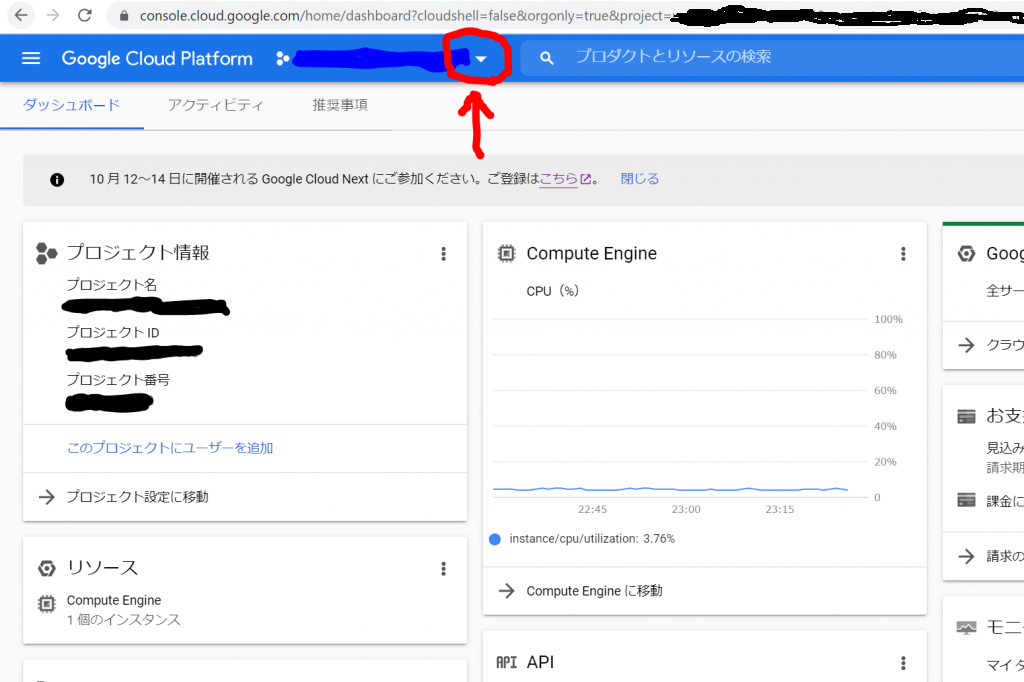
すると、アイコンが表示されたり、なにやら作成中の雰囲気を出したあと、プロジェクトのダッシュボードが表示されました。が、、、これは今作ったプロジェクトではありませんね。そこで下向きの三角形をクリックしてプロジェクト一覧を表示します。
すると、以下のような一覧が見えますが、先ほど作ったプロジェクトが見当たりませんね。以下の「すべて」のところをクリックするか、虫眼鏡アイコンの隣の「プロジェクトとフォルダを検索」へ「Sample」と入力すれば、先ほど作成したプロジェクトが現れます。
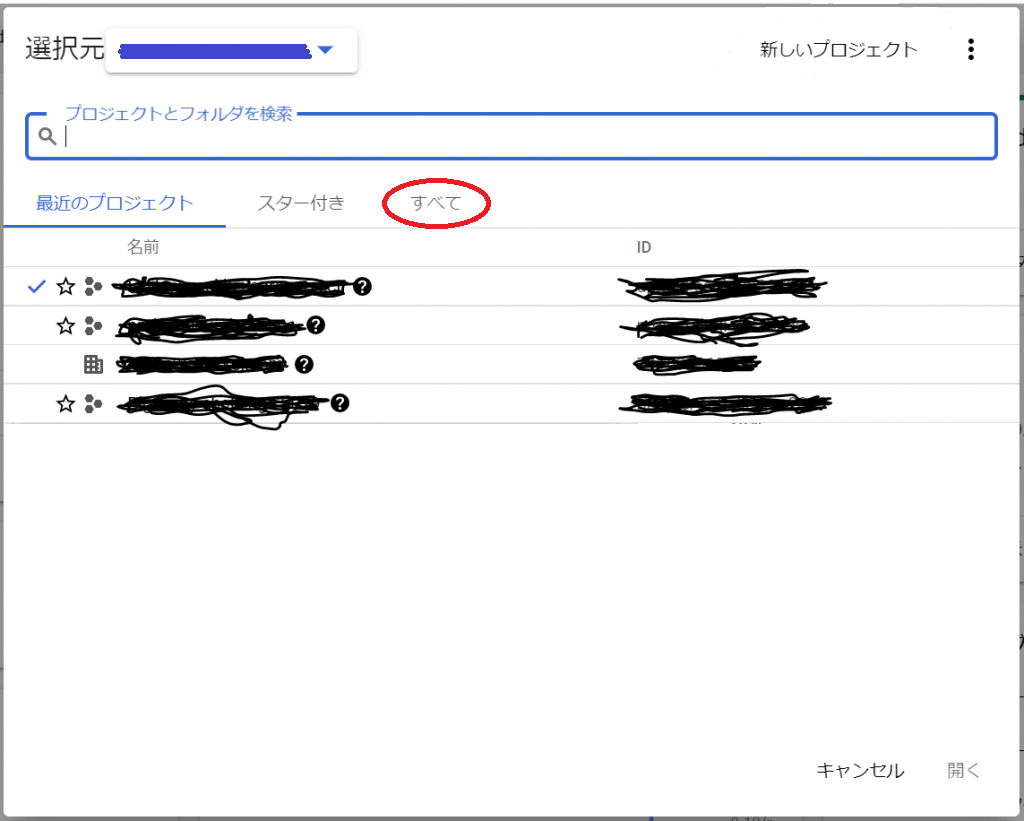
では、「すべて」をクリックしてみましょう。
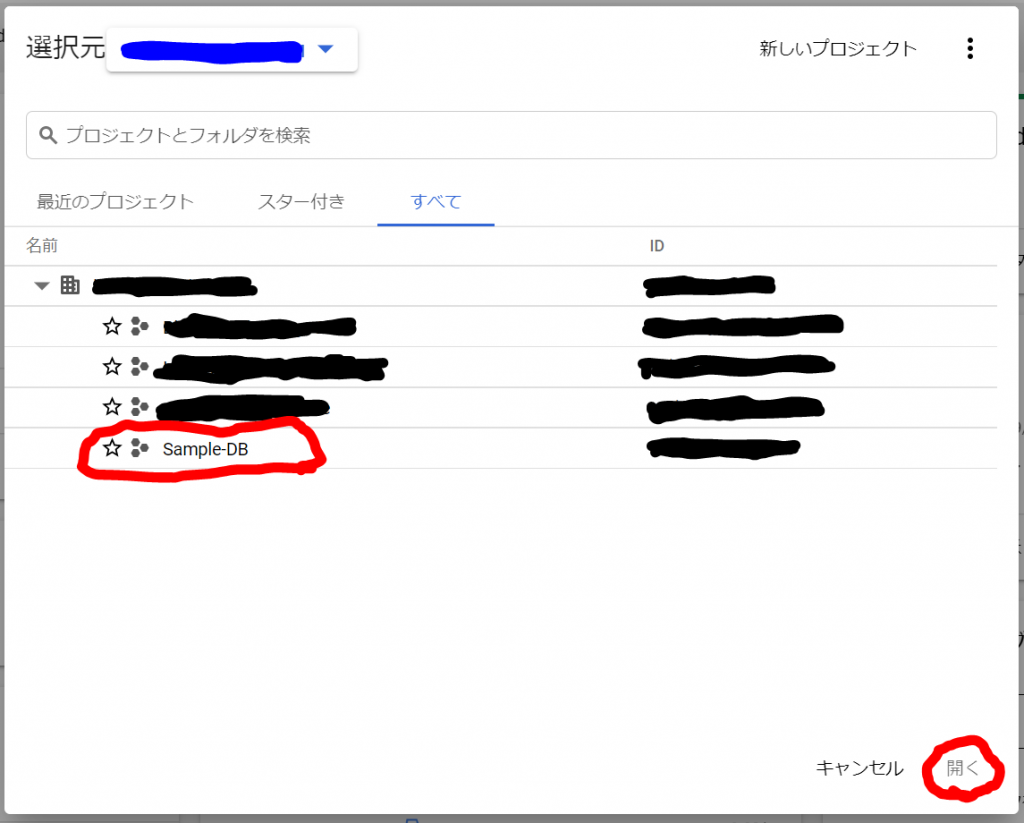
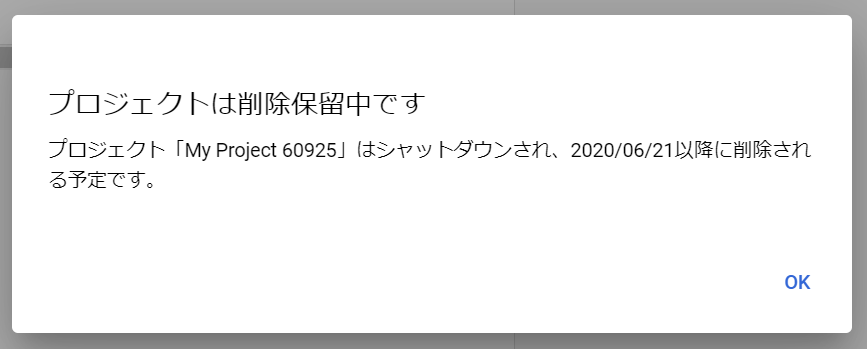
見つかりましたので、「Sample-DB」を選択して「開く」をクリックしてみましょう。以下の通り、プロジェクトの作成に成功しました。プロジェクトを作っておくと請求情報をプロジェクト単位でみられる等、管理しやすくなると思います。
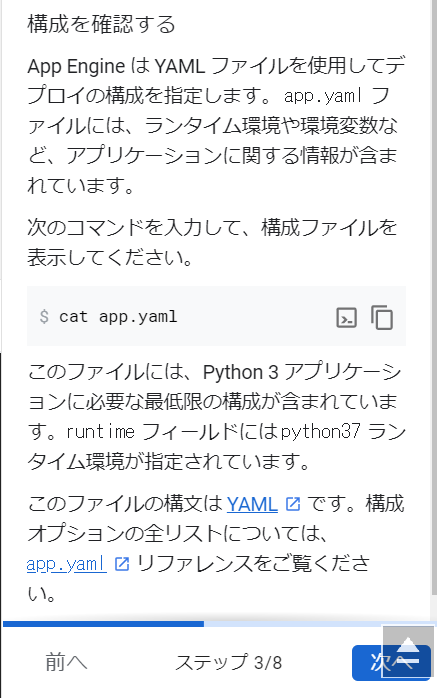
Cloud SQLのMySQLインスタンスを作成してみる
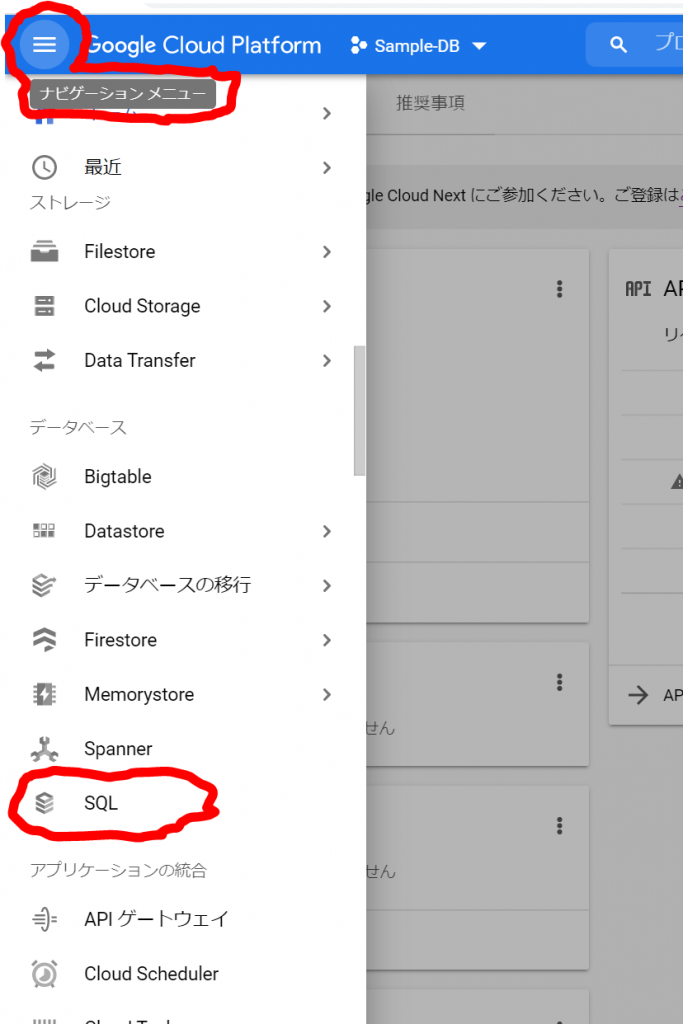
では、次にCloude SQLのMySQLを作成してみます。ナビゲーションメニューの「データベース」カテゴリから「SQL」を選択します。左上の横線三本のハンバーガーマークをクリックするとナビゲーションメニューが表示されますので、メニューを下の方へ下げて行って、「SQL」を探してください。
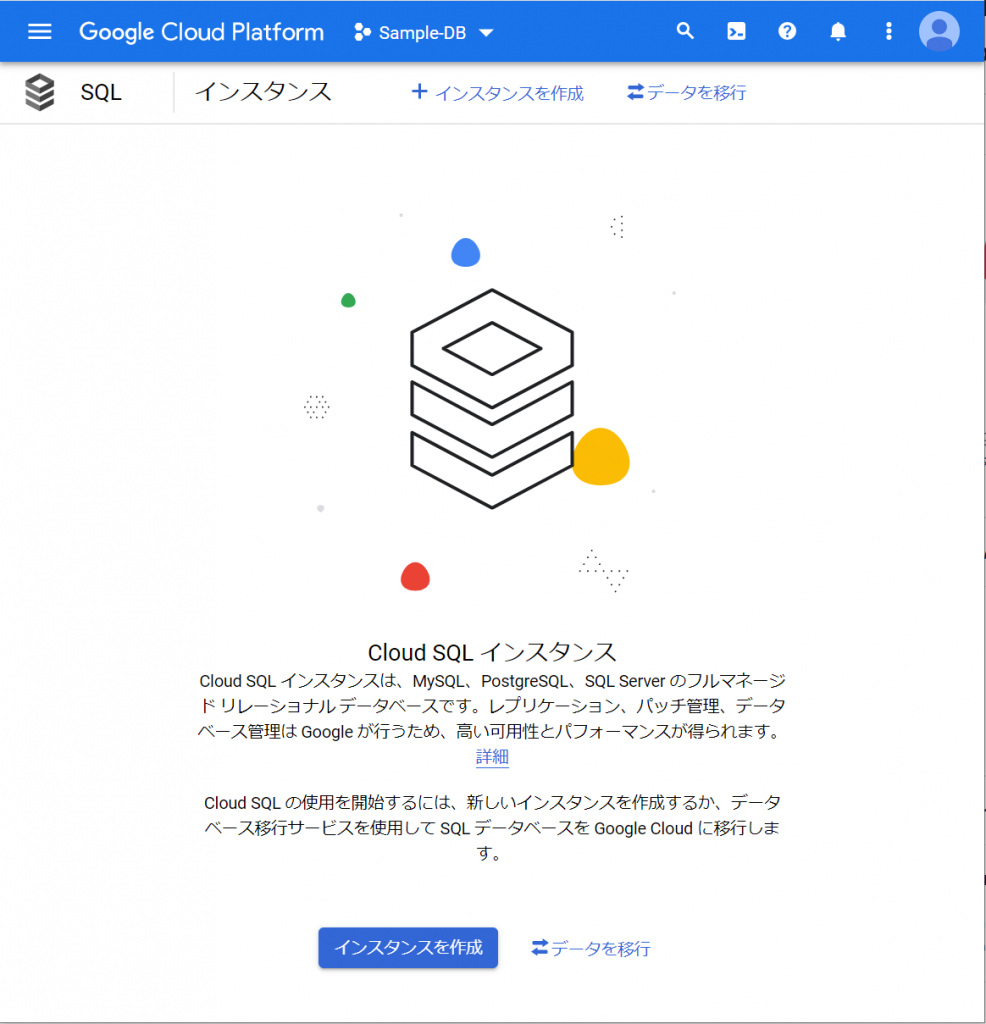
「SQL」をクリックするとCloude SQL インスタンスを作成するためのウィザードが始まりました。次は、当然「インスタンスを作成」ですね。既存システムのデータを持っていれば、データの移行もできるようですね。企業システムでのリプレース案件だと結構利用するタイミングがありそうなので、気になりますね。いやいや、今回はまずインスタンスを作成しますよー。(ちょっと調べてみたら、今のところ、MySQLとPostgreSQLで利用可能で、SQL Serverは、まもなく利用可能ということです。2021年9月23日現在)
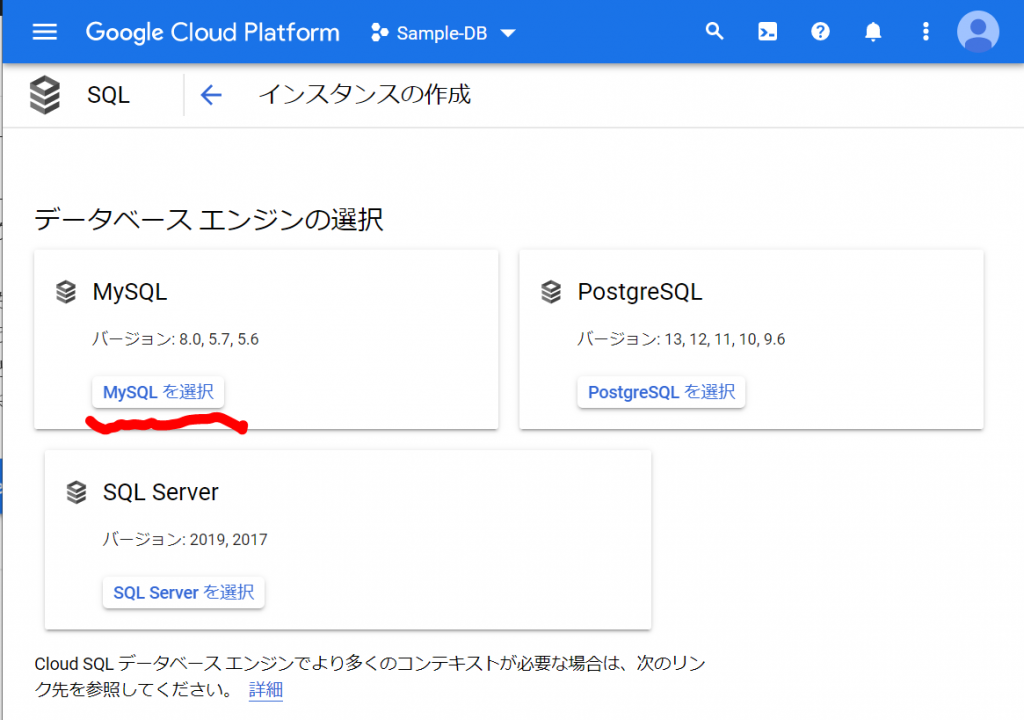
よく読んでみると、「MySQL」「PostgreSQL」「SQL Server」のインスタンスが作成できるようですね。では、「インスタンスを作成」ボタンをクリックします。以下のような表示になりました。今回は「MySQL」を選択します。
「MySQL を選択」をクリックすると以下のような画面になりました。
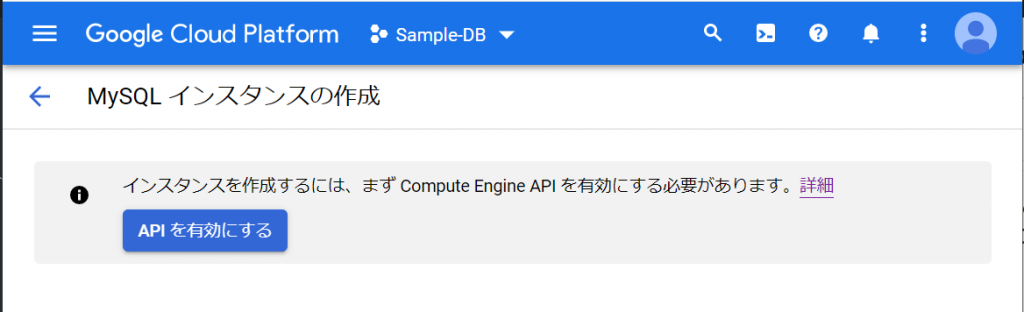
ふーむ、何々、「インスタンスを作成するには、まずCompute Engine APIを有効にする必要があります。」ですか。なるほど。と、いうことはMySQLインスタンスはCompute Engineを利用して実現しているのですね。いきなりMy SQLインスタンスって、どうやって起動するんだろうか、と、思っていましたが、仮想マシンを実行して、その上で動かす、ということなのでしょうね。ま、完全な想像ですけど。そして、このホームページはCompute Engineを利用しているので、この設定は不要なのでは、と、思いましたが、プロジェクトごとに設定が必要なのか、APIとは別の設定なのかのどちらかでしょうね。いずれにせよ、APIを有効にしないとどうにもならないので、「APIを有効にする」をクリックします。

しばらく上記のようにくるくるしてから、以下のようになりました。
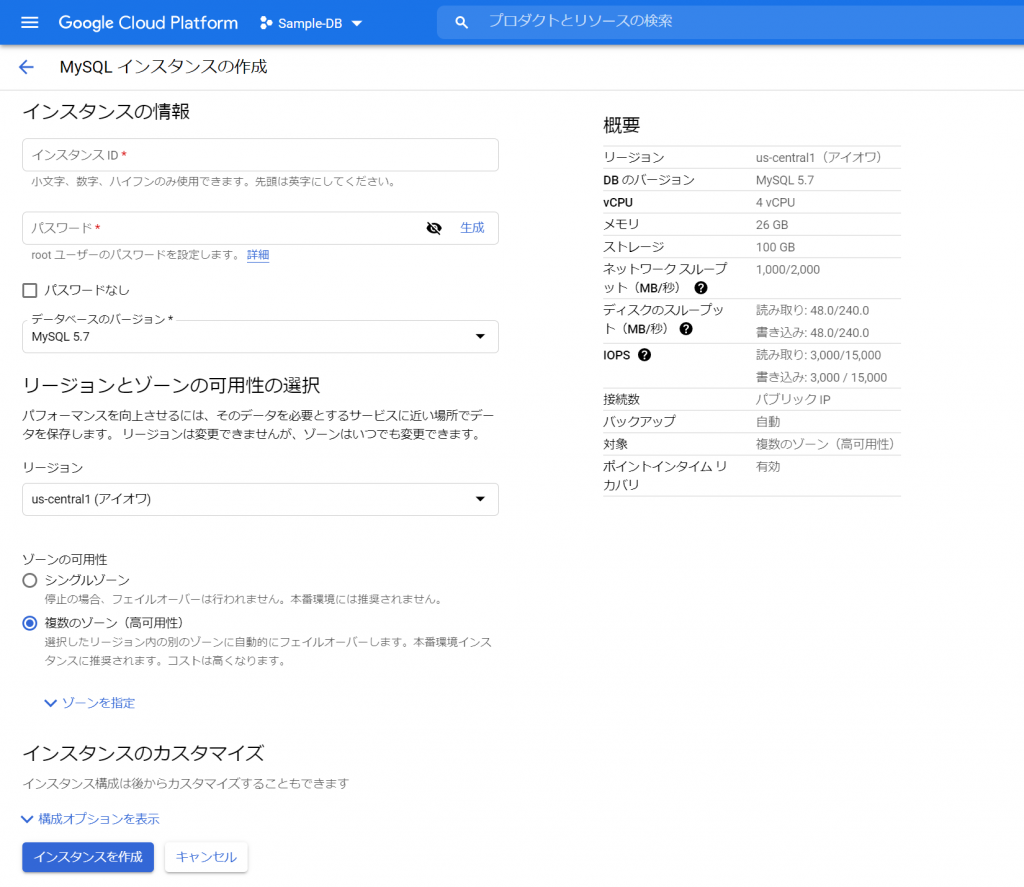
必須入力は、「インスタンスID」と「パスワード」のみですね。今回はお試しで作ってみるだけなので、最小構成にしたいですね。データベースのバージョンは、8.0、5.7、5.6から選べました。おそらく初期値の「5.7」は安定したバージョンなのでしょうね。今回はお試しなので、8.0を選択しておくことにします。インスタンスが作成され、常時存在することになるので、インスタンスを起動している間は使用料がかかります。金額については、概算ですが、Cloud SQL for MySQL の料金で、計算できるようです。リージョンの選択によって若干金額が変わってきます。現時点のアイオワでは、1仮想CPUあたり、1か月で$30.15、1GBあたり、1ヶ月で$5.11です。東京は$39.19、$6.64なので、やはり若干高くなっていますね。業務で利用する場合は、ネットワークの距離の影響もあるので、慎重に選ぶ必要があるかと思いますが、今回は安い方のアイオワで問題ありませんね。そして「ゾーンの可用性」ですがこちらは「シングルゾーン」に変更しましょう。複数のゾーン(高可用性)を選択すると、およそ料金が二倍になります。ま、二台用意しておいて、一台がダメになったとき切り替えてダウンタイムを極小にしよう、という取り組みですから、ま、そうなりますよね。そして、vCPU数が4に、メモリ、26GBもいらないでしょう。こちらは、「構成オプションを表示」を選択することで設定できるようになっていました。
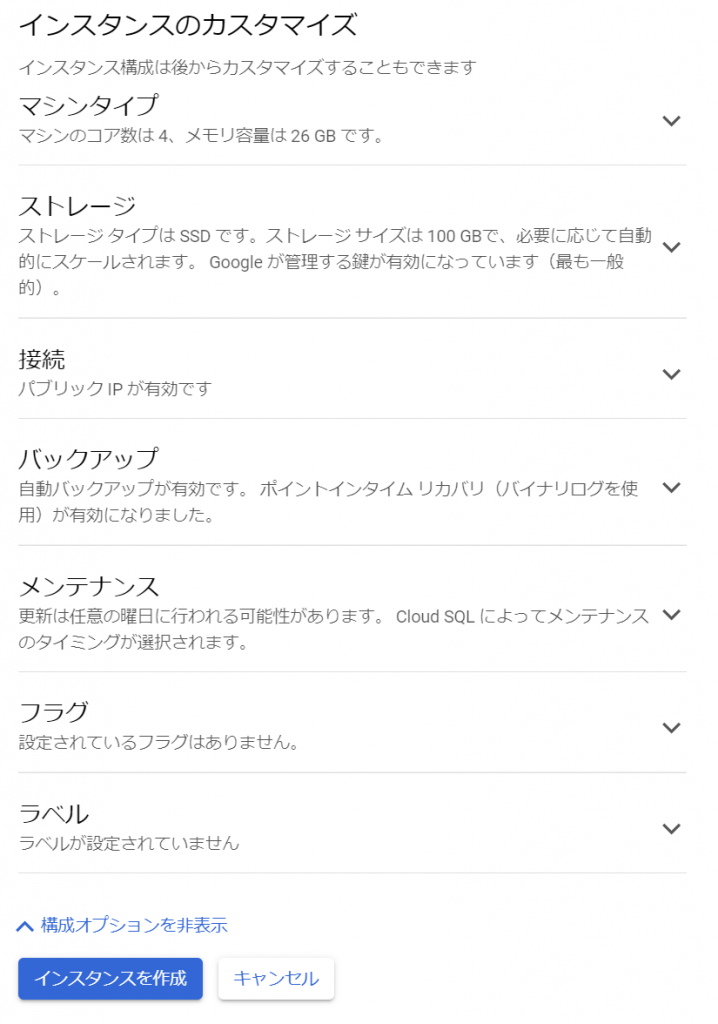
へえ、インスタンス構成は、あとから更新することもできるのですね。ま、ちゃっちゃと最小構成を目指して片づけてしまいましょう。まずは、マシンタイプですね。
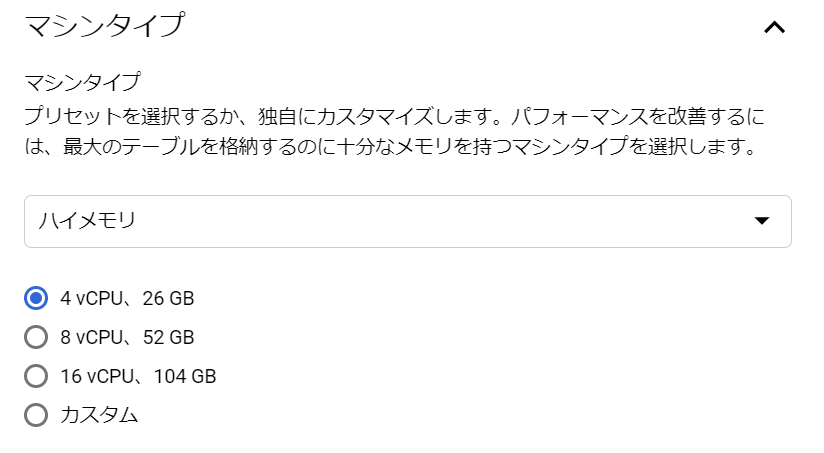
おや、4 vCPU、26GBが最小構成なのでしょうか、、、あ、違いました。「ハイメモリ」が選択されている状態でしたね。ちょっとクリックして中身を覗いてみましょう。
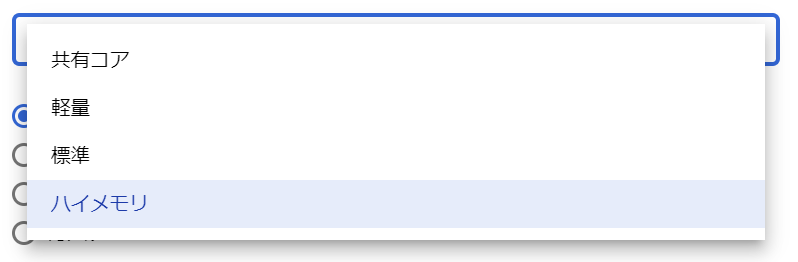
なるほどねぇ、順番的には「共有コア」が一番軽量なのでしょうか。以下に、一覧にしてみました。
- 共有コア
- 1vCPU、0.614GB
- 1vCPU、1.7GB
- 軽量
- 1vCPU、3.75GB
- 2vCPU、3.75GB
- 4vCPU、3.75GB
- カスタム※
- 標準
- 1vCPU、3.75GB
- 2vCPU、7.5GB
- 4vCPU、15GB
- カスタム※
- ハイメモリ
- 4vCPU、26GB
- 8vCPU、52GB
- 16vCPU、104GB
- カスタム※
※カスタムは、vCPUが1~96まで入力可能(1より大きい場合は偶数)で、メモリがvCPU数(N)に応じておよそ、3.75+1.75×(N-4)/2+0.25×INT((N-2)/10)[N<6は3.75]~6.5×N GBの範囲で変更されました。
と、いうことで、今回は「共有コア」の1vCPU、0.614GBを選択します。
次は、ストレージですね。
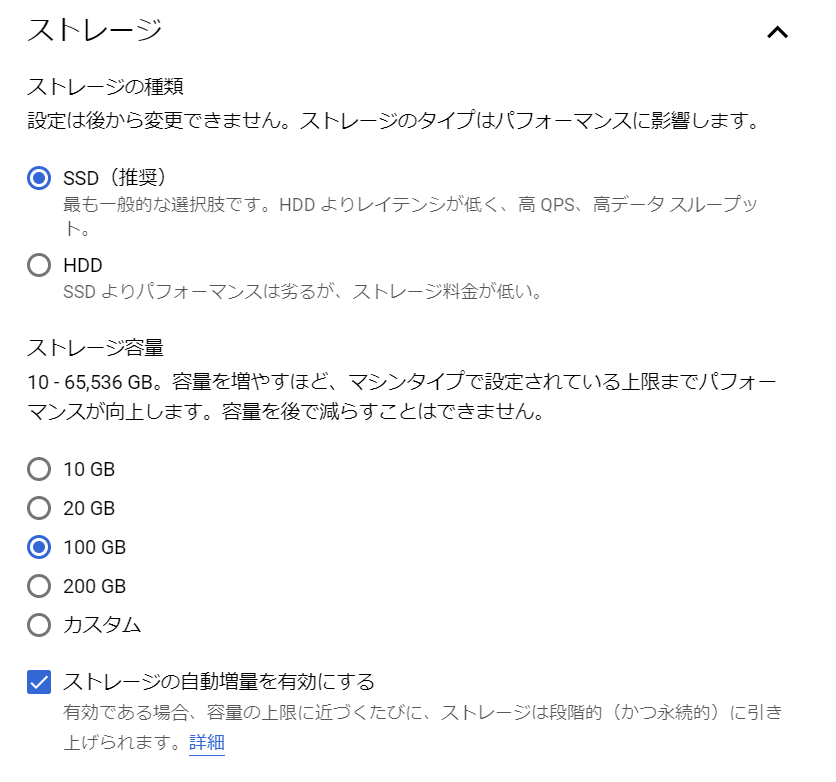
SSDとHDDですね。やはりHDDの方が安価ですね。どれくらい違うのかというと、1GBあたり、アイオワリージョンでは、SSDが$0.170/月、HDDが$0.090/月、東京リージョンでは、SSDが$0.221/月、HDDが$0.117/月ということのようです。パフォーマンス要件はありませんので、ま、ここはHDDを選択しておきましょう。
ストレージ容量は、10GB、20GB、100GB、200GB、カスタムですが、こちらも最小要件の10GBを選択します。容量を増やすほどパフォーマンスが向上する、ということが書いてありますが、どうしてでしょうね。もしかしたら、ディスクへのアクセスをうまく分散できるのかも知れませんね。ストレージの自動増量を有効にする必要は、まったくありませんが、ま、利用しなければ影響ありませんので、そのままにしておきましょう。
次は、「接続」ですね。
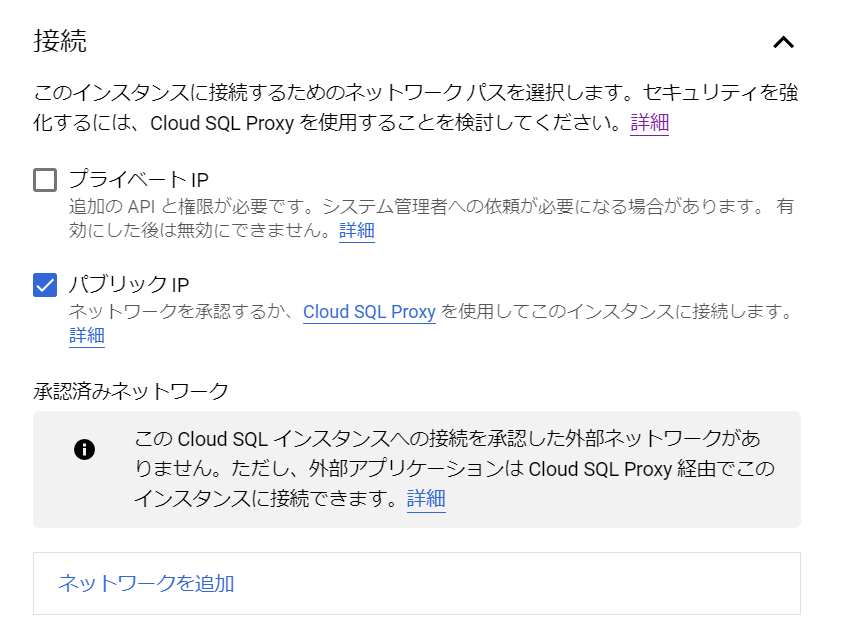
おすすめは、Cloud SQL Ploxyを使って接続してください、ということのようです。プライベートIPはVPCのみの内部(プライベート)IPアドレスで、インターネットにアクセスできるのが外部(パブリック)IPアドレスになります。Webアプリケーションの一部としてのデータベースなら、プライベートIPアドレスのみ有効にすればよいでしょうか、これは構成によりますね。今回はお試しなので、このままの設定でよいでしょう。
次に、バックアップの設定ですね。今回のお試しではバックアップなしでよいのですが、ちょっと内容は確認しておきましょう。
「バックアップを自動化する」はデフォルトでチェックが入っていますが、時間枠で選択するようですね。マルチリージョンを選択しておけば複数のリージョンにバックアップされるのでとりあえず安心ですね。リージョンを選択すると、特定のロケーションをセットする必要があります。バックアップの数が7にセットされていますが、1週間であれば、特定のタイミングまで戻せますよ、という感じでしょうか。ポイントタイムリカバリを有効にすると、詳細オプションにログを保持する日数を設定できるようになりました。デフォルトは7日でした。
ま、ここは、「バックアップを自動化する」はチェックを外しておきます。サンプルですから、バックアップ必要ありません。実際に稼働するシステムならもっとまじめに考えないといけませんけどね。あ、このチェック外すと「ポイントインタイムリカバリを有効にする」は触れなくなりました。普通のバックアップも取得していないのに、復元はムリですよ、ということですね。
次は、メンテナンス項目ですね。ちょっと見てみましょう。なるほどねぇ、デフォルトだと、短期間だけど中断してしまうのですね。
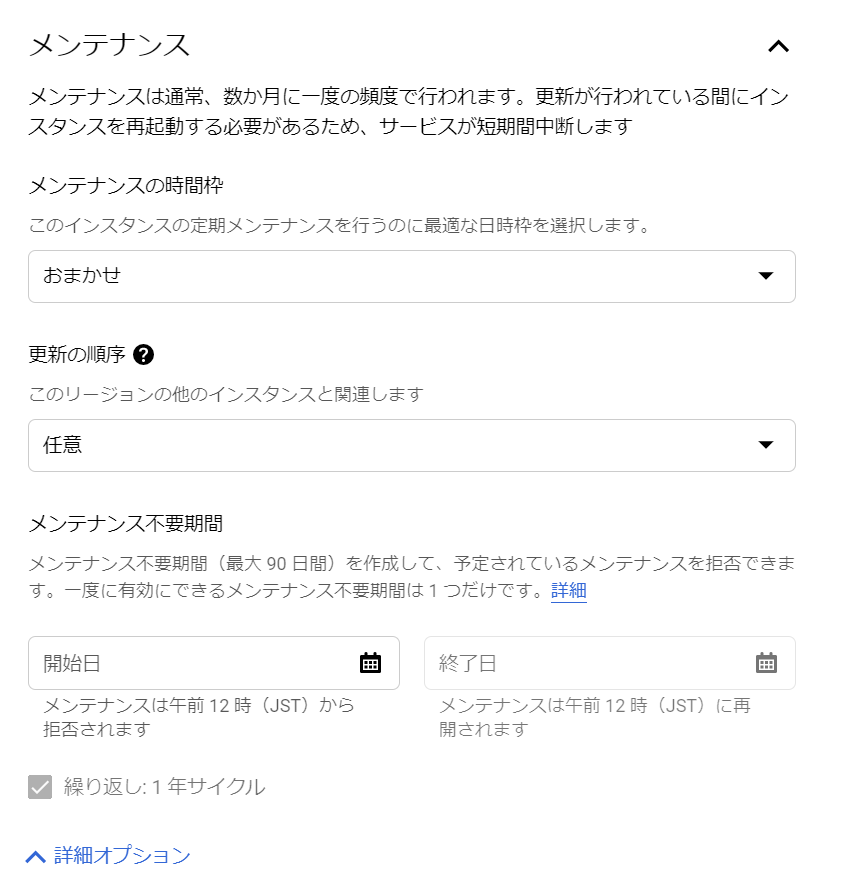
メンテナンスの時間枠は、「おまかせ」以外は「土曜日」~「金曜日」でした。曜日単位で指定するのですね。一般的な企業なら、土日が選ばれるのでしょうね。更新の順序は「任意」「後で」「早め」の三択でした。これは面白いですねぇ。バージョンアップを適用する時期を早めにするのか後でやるのか、それともお任せなのか、設定するのですね。あと、メンテナンス不要期間も設定できるのですね。今回はお試しで、すぐ削除してしまおうと思っているので、設定はこのままにしておきます。
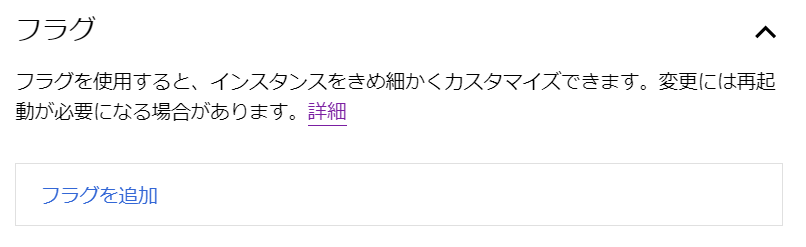
「フラグ」では、MySQLのパラメータやオプション、インスタンス構成や調整など、様々な設定ができるようです。これはMySQLに精通しないとなかなか設定は難しそうですね。今回は不要ですが、チューニングや調査が必要な局面があるときにはここで設定可能ですね。いざというときのために覚えておきましょう。
やっと、最後の項目、「ラベル」です。
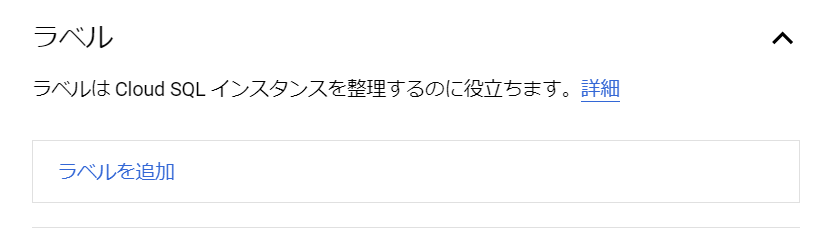
「ラベル」を追加すると、インスタンスを区別したり、請求料金を分析したりすることができるようです。今回は放置しておきます。
やっとひととおりの設定を眺め終わりました。
インスタンスの作成
やっと、「インスタンスを作成」をクリックしました!ここまで読んでくれたひと、いますかねぇ。。。
あら、インスタンスIDと、パスワードがない、と、叱られました。もうすっかり失念しておりました。
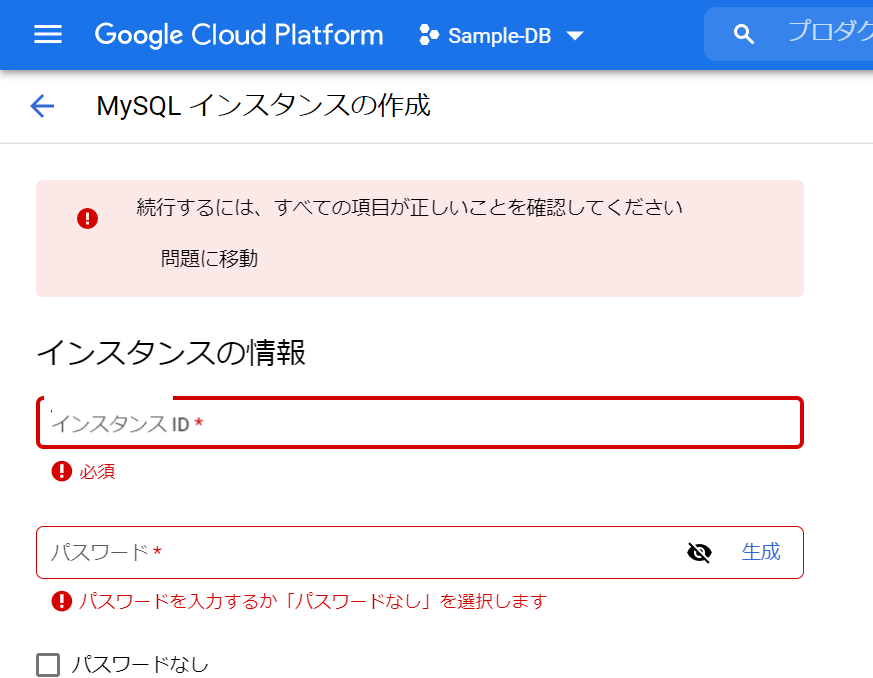
インスタンスIDは、何でもよいのでしょうかねぇ。「Sample-DB」を入れてみます。そして、パスワードは「生成」をクリックしてみましょう。

ちょっと理解に苦しみますが、、、これは、大文字がダメだった、ということでしょうか。小文字に変えてみます。予想通り、小文字なら大丈夫でした。「生成」も成功したので、今度こそ、「インスタンスを作成」をクリック!
一瞬、「インスタンスを作成しています。」のようなメッセージが出た後、画面が切り替わり、しばらく「アップロードとSample-DBのオペレーション」の「sample-dbを作成しています」が右下に表示されます。
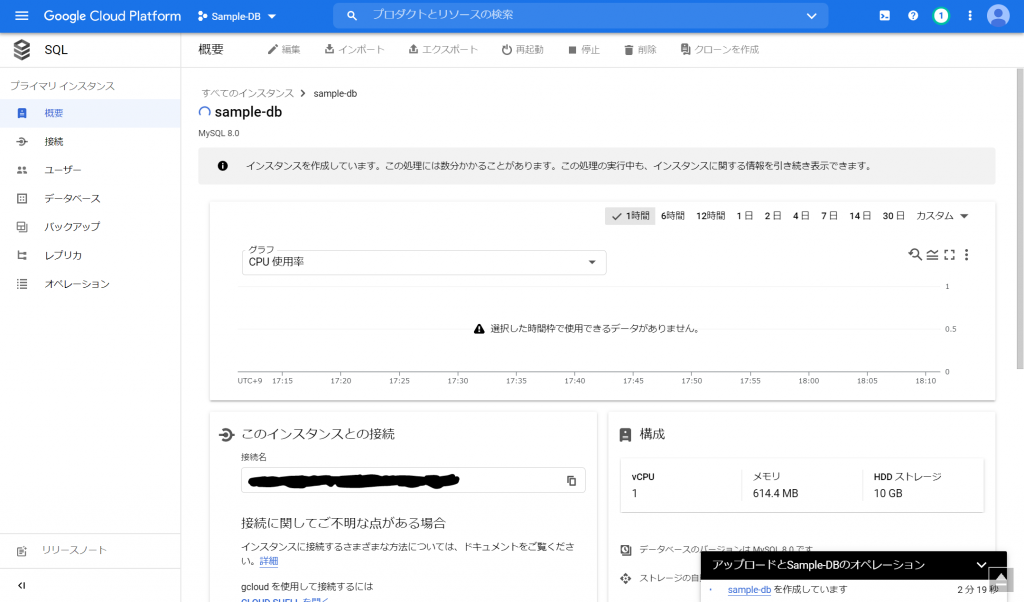
まだ、作成中のような気がしますが、一応、できたのかな。いや、もうしばらく待ってみましょう。。。と、いうことでインスタンス作成完了まで、11分とちょっとかかりました。できました!
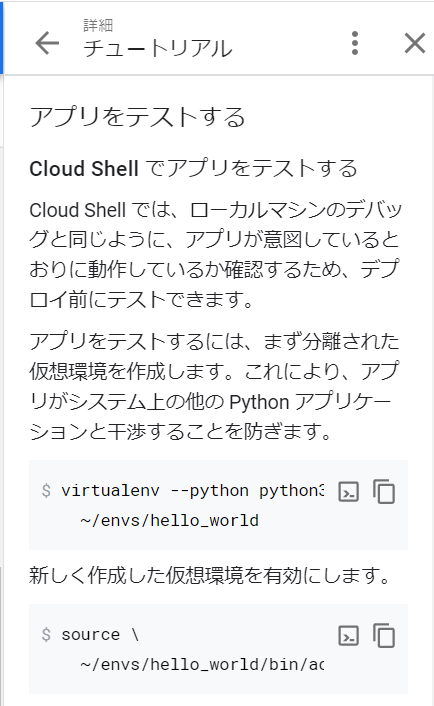
データベースの作成
次はデータベースを作成します。MySQLはデータベースを複数作成できる、ということで作成してみます。
Cloud SQLの「データベース」メニューを選択します。
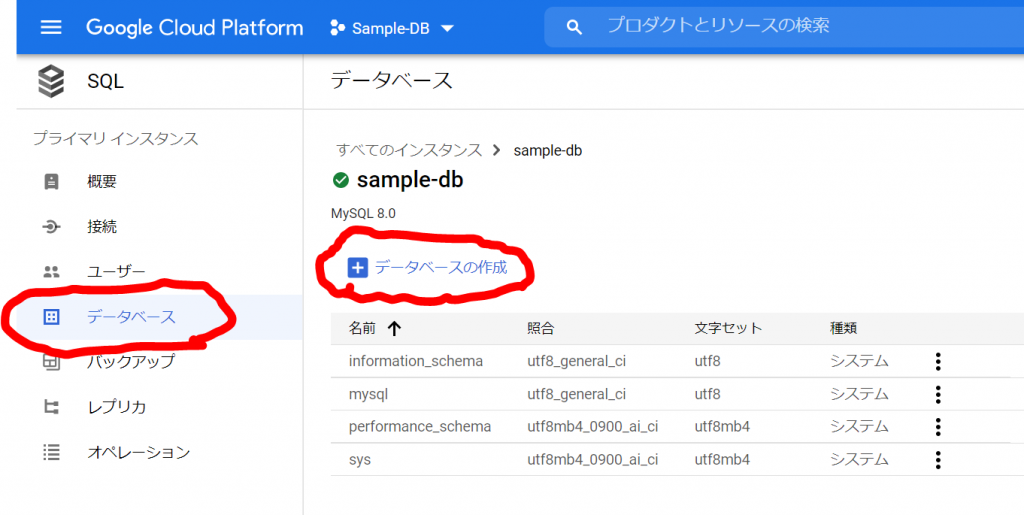
「データベースの作成」をクリックしてみます。

「データベース名」は何にしましょうかねぇ。ルールがあるようですが、とりあえず「Sample-DB」と入力してみます。
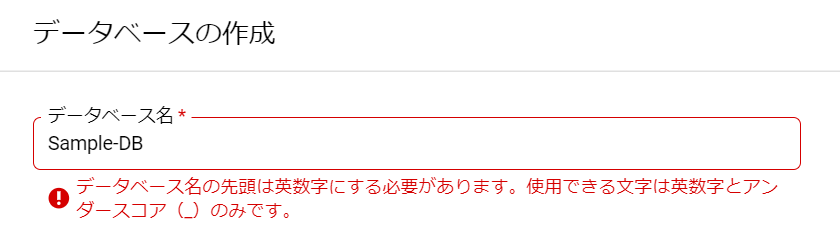
おお、なるほど、英数字とアンダースコアなので、ハイフンがダメなのですね。ハイフンをアンダースコアに変更してみます。
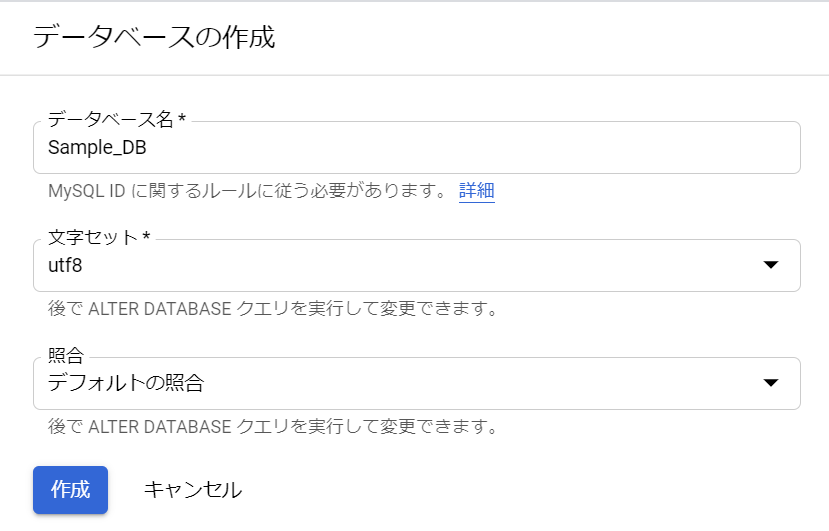
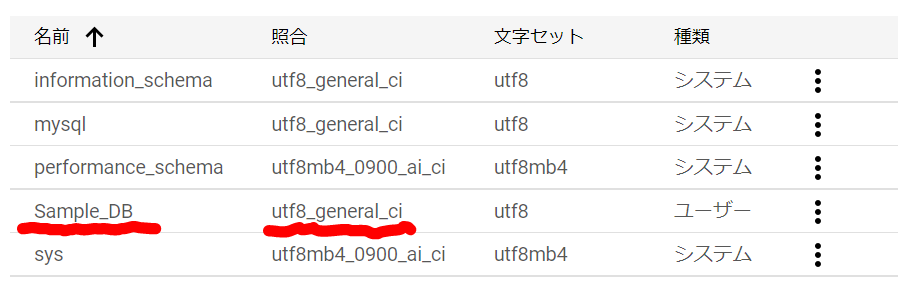
オッケーでした。「文字セット」と「照合」を決めなければいけませんね。utf8はいいけど、「照合」って何でしょうね。選択値は「utf8_bin」とか「utf8_czech_ci」とか文字コードっぽいですね。選択した「文字セット」によって、選択値が変わりました。ま、後で変更できるようなので、デフォルトでも問題ないでしょう。「作成」をクリックします。一瞬作成中のような雰囲気になりましたが、すぐにできました。「照合」は「utf8_general_ci」が選択されたようですね。
テーブルの作成
次にテーブルを作成します。まずは、MySQLに接続しなければいけないのですが、、、どうやるのでしょうか。「概要」の「このインスタンスと接続」にありました!
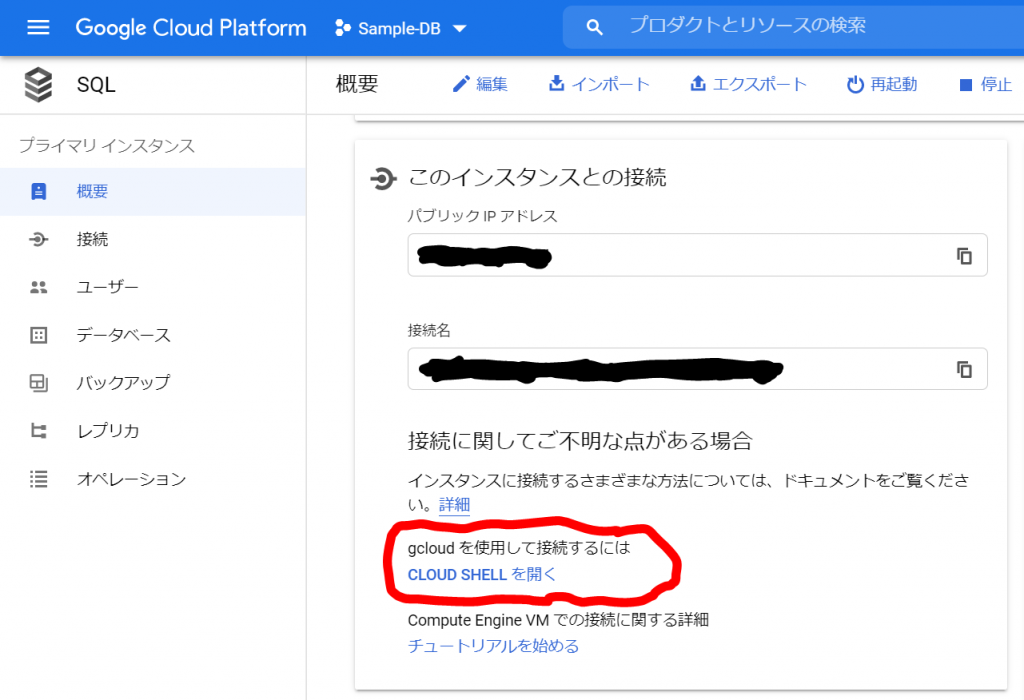
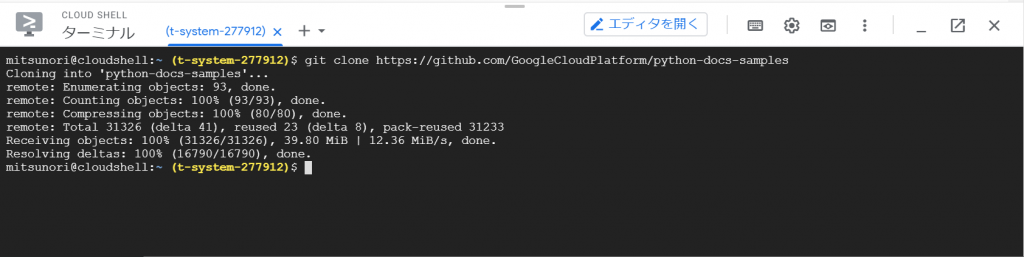
インスタンスに接続するさまざまな方法については、ドキュメントに書いてあるようですが「詳細」はあとにして、「CLOUD SHELLを開く」をクリックしてみました。

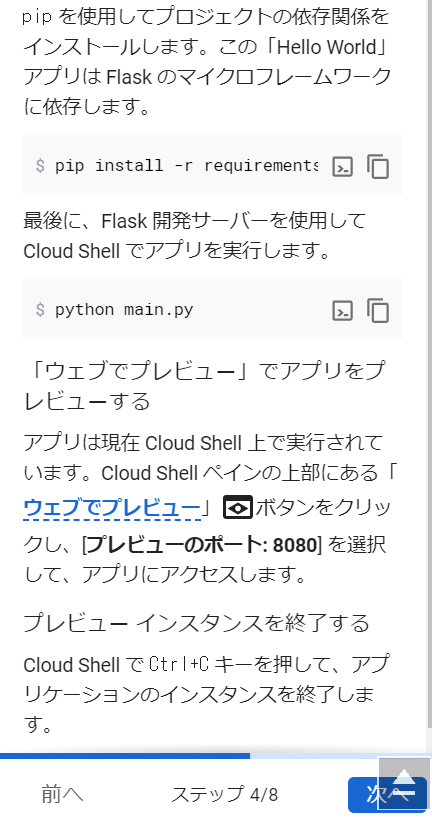
gcloud sql connect sample-db –user=root –quiet
というコマンドで接続できるようです。Enterキーを入力したところ、、、
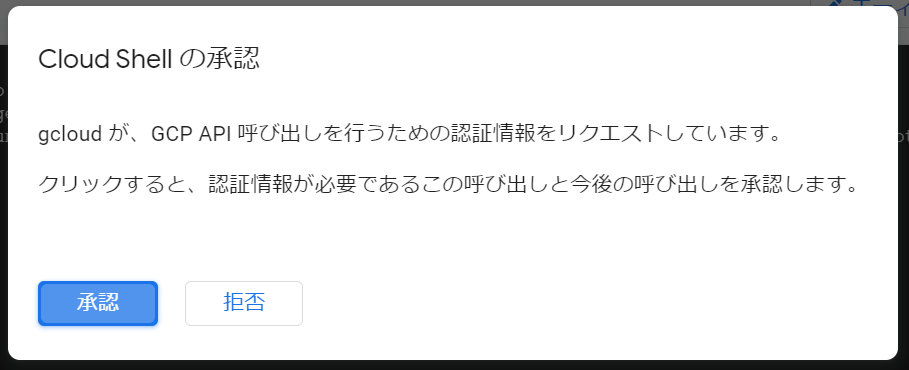
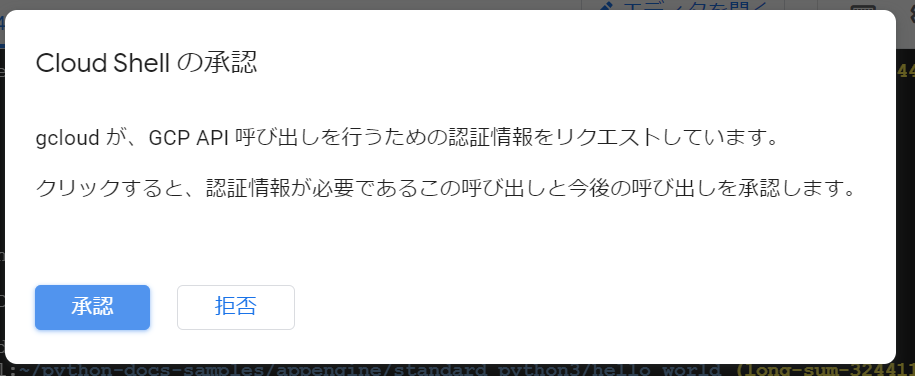
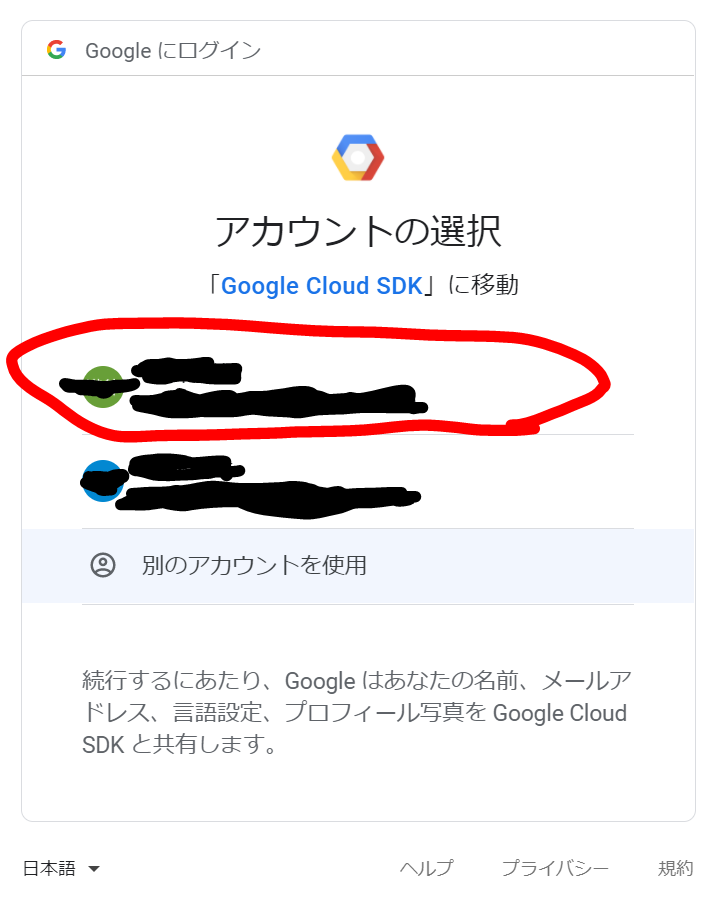
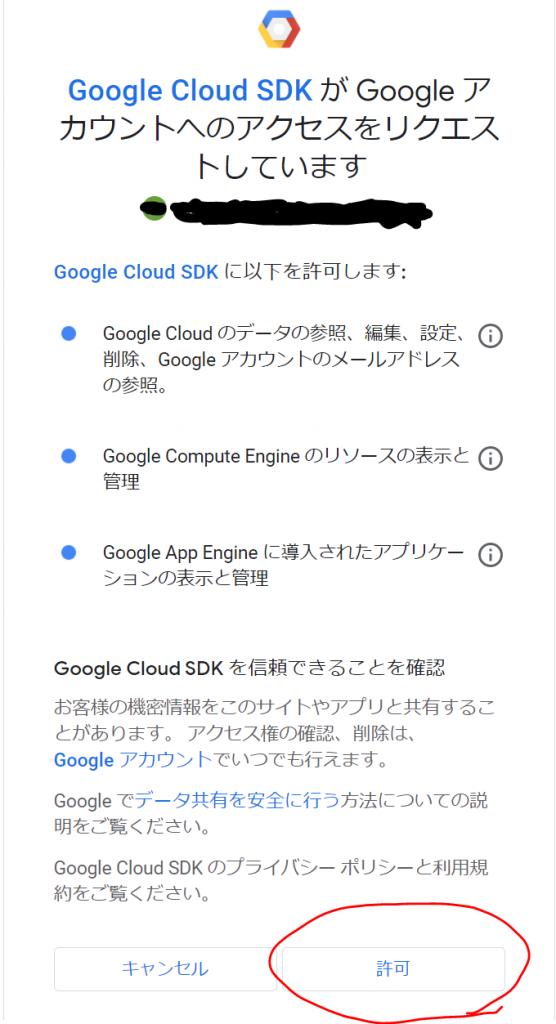
Cloud Shellの承認画面が表示されました。「承認」をクリックします。
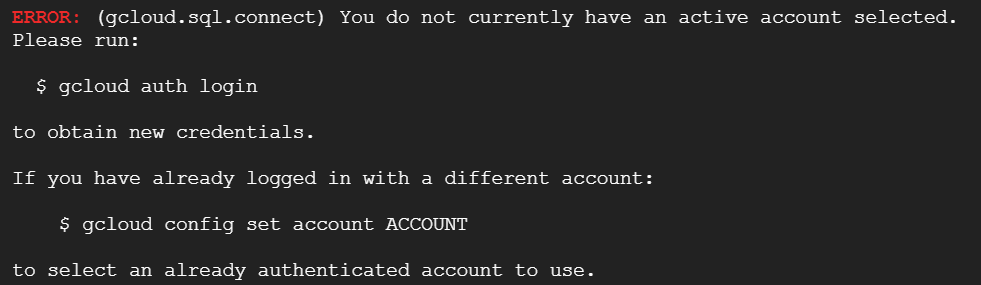
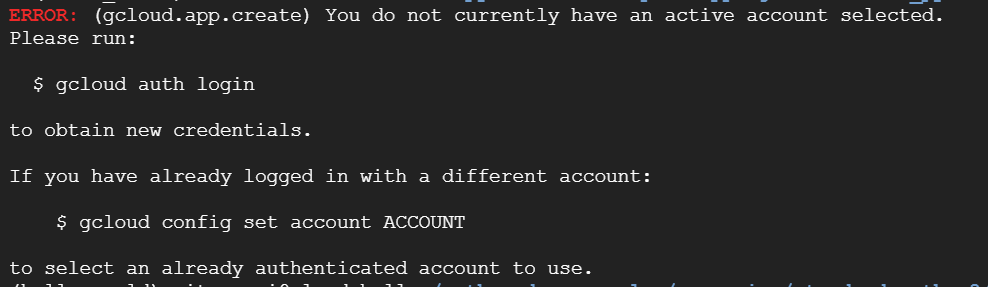
おお、アクティブなアカウントが選択されていない、と申されましても。。。現在どのアカウントでログインしているのでしょうか。試しにもう一回実行してみます。おや、エラーが変わりました。

今度は「Cloud SQL Admin API」がこのプロジェクトではまだ使われておらず、有効になっていない、ということのようです。APIを有効にするには、表示されたURLをクリックせよ、ということでクリックしてみますと、ブラウザで別のタブが開きました。
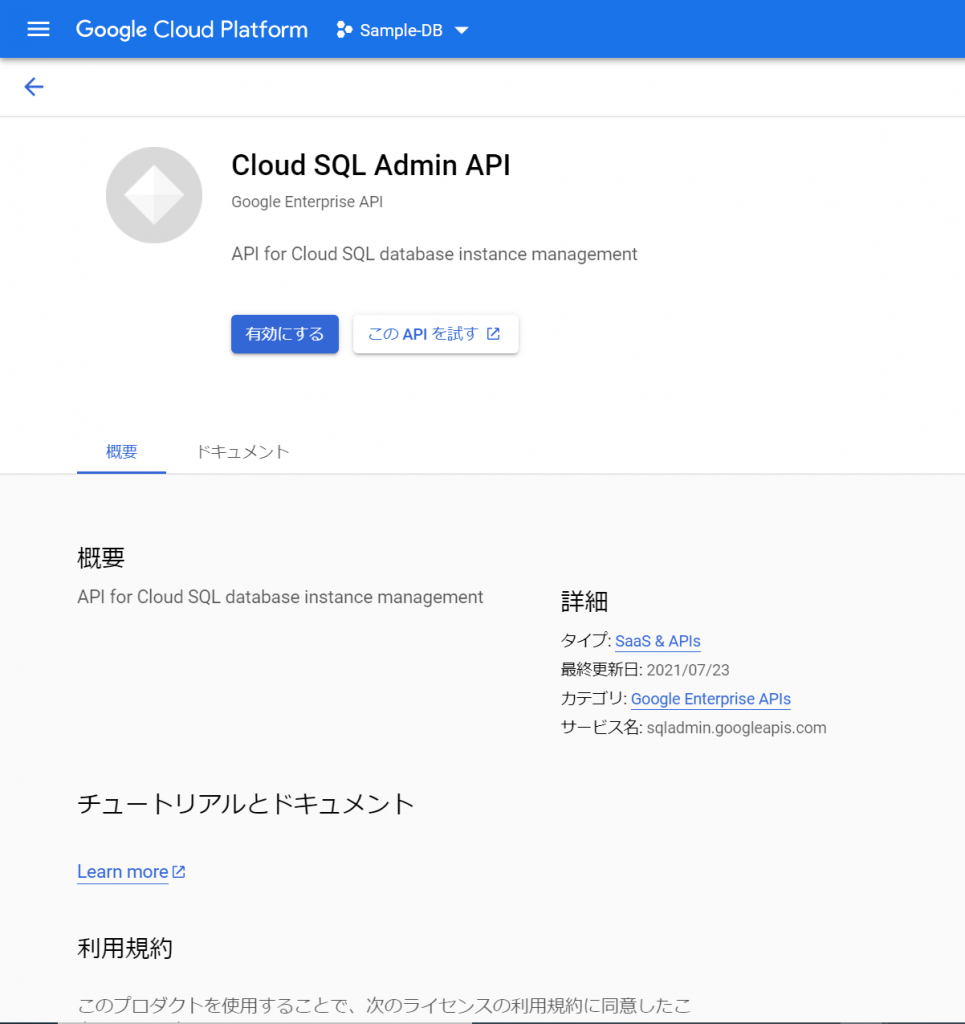
なるほど、「gcloud sql」コマンドを使うには、このAPIを有効にしないといけないのですね。承知いたしました。「有効にする」をクリックします。くるくるして、次の画面が表示されました。
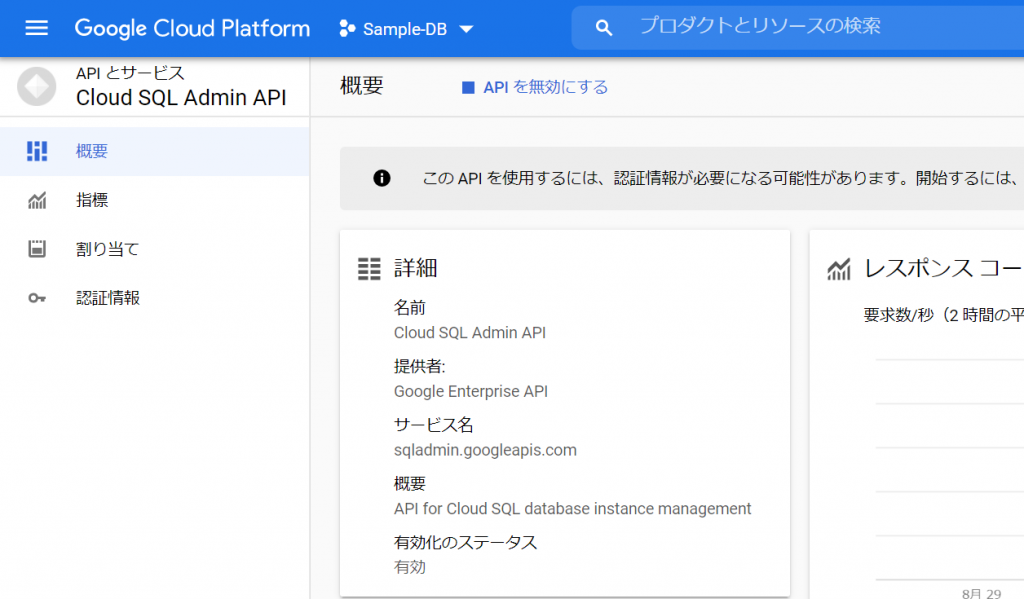
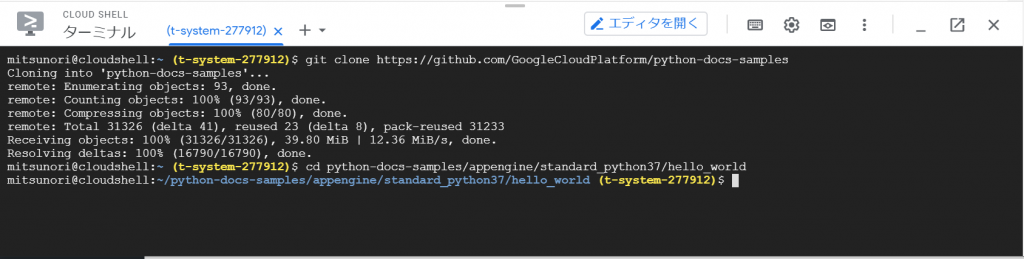
とりあえず、Cloud SQL Admin APIが有効になったようです。ターミナルから再度実行してみます。

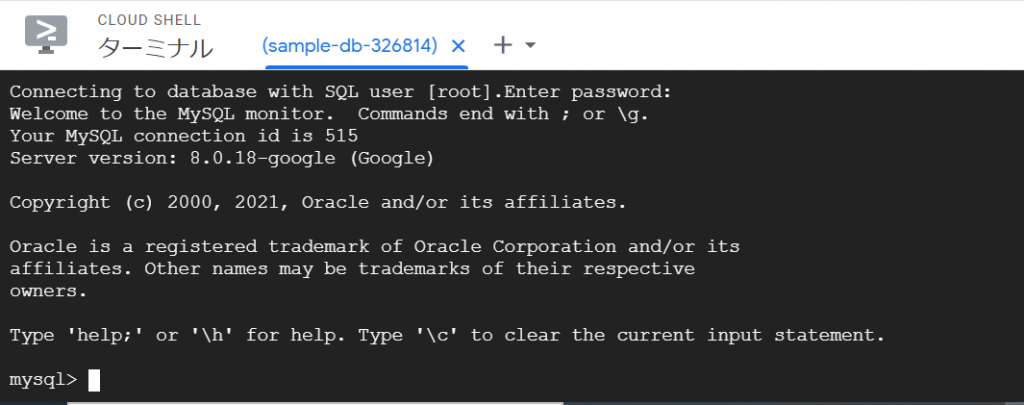
おお、コネクションのために5分必要なのでしょうか。。。パスワードを聞かれたので、先ほど自動生成したパスワードを入力して、Enterキーを押下すると、、、できました!!!
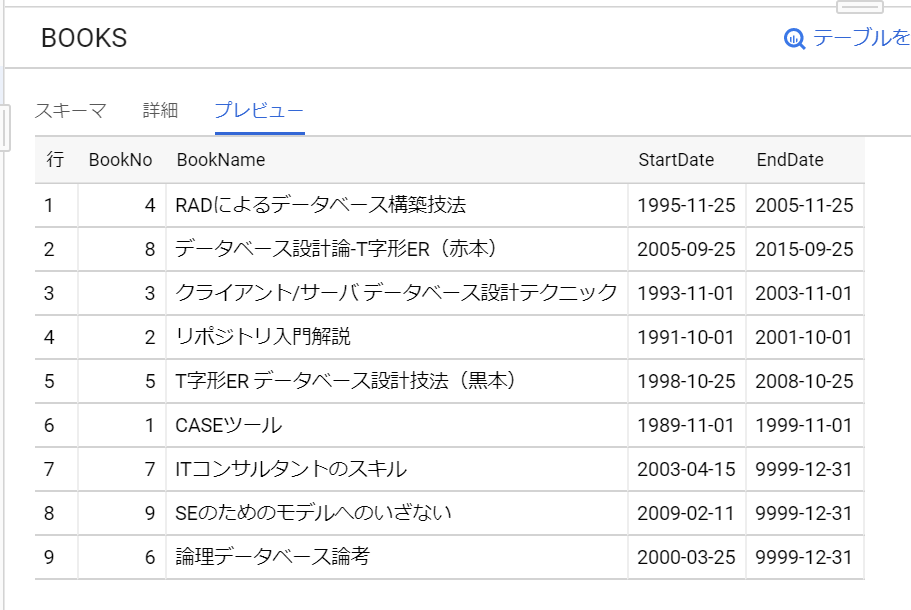
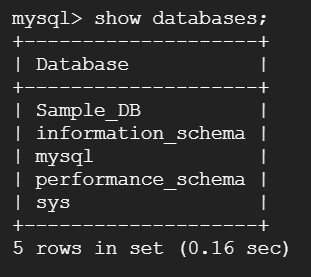
先ほど作ったデータベースを確認してみましょう。「show databases;」と入力してみます。
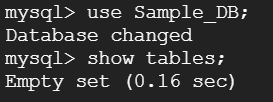
次に、データベースの選択ですね。「use Sample_DB;」を実行して、テーブルが無いことを確認します。「show tables;」を入力してEnterキーを押下します。
やっと、テーブルが作成できます!「create table sample_table ( id int auto_increment, t text, primary key(id) );」実行してみます。さらに結果を「show tables;」で表示してみます。
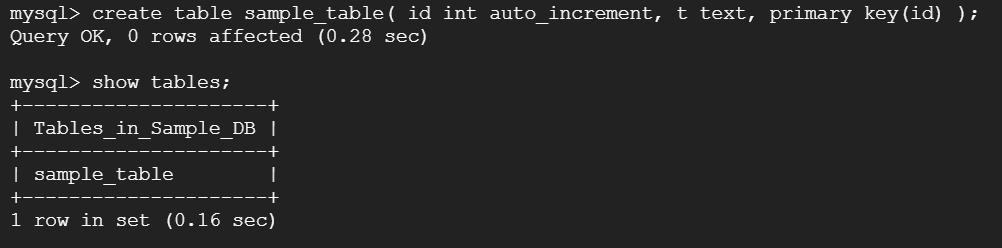
データをインサートしてみます。

入りました。念のため、結果を確認します。
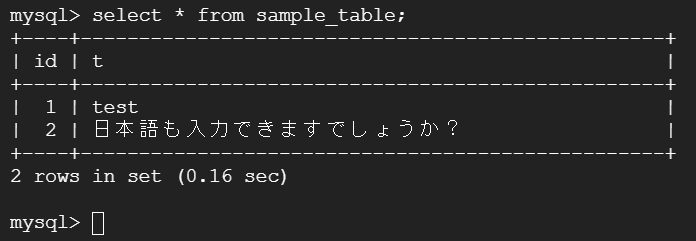
できました!
インスタンスの停止
サンプルでしか使わないインスタンスですので、すぐに終了します。インスタンスが存在していると、利用していなくても放置しているだけで、課金されてしまいます。
念のため、先ほどの接続ですが、データをコミットして、終了します。
「概要」から「停止」をクリックします。
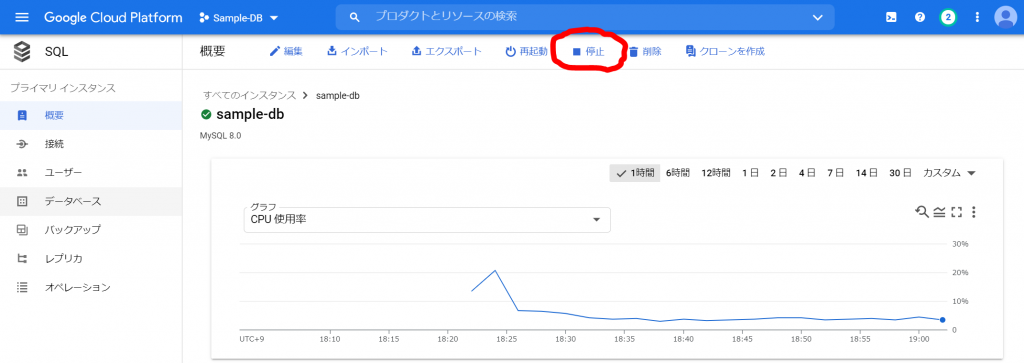
すると、以下のようなメッセージが表示されますので、「停止」をクリックします。
停止しました。
追記(2021-09-30)
作成直後に確認したときは、請求予定金額が0円でした。作成には請求がかからないようになっている、というのもちょっと変な話なので、タイミングを改めて請求金額を確認してみようと思っていて、確認してみました。
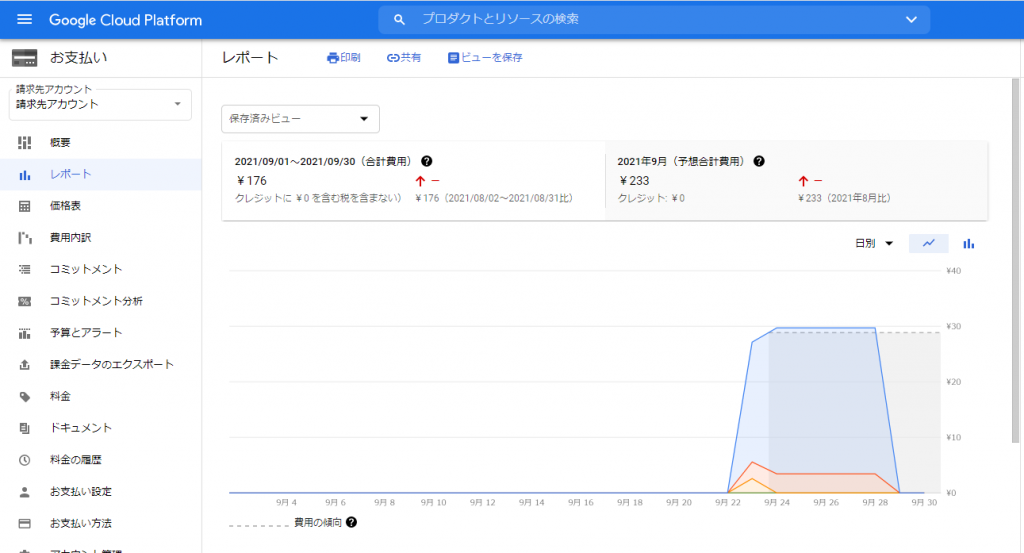
およそ一週間で176円、ということでした。データベースインスタンスを停止したので、もう課金は発生しないはず、というふうに思っていたのですが、予想が外れました。一体何に課金されているのでしょうか。ということで見てみました。
- Cloud SQL for MySQL: Zonal – IP address reservation in Americas 139.62 hour ¥154
- Cloud SQL for MySQL: Zonal – Low cost storage in Americas 1.97 gibibyte month ¥19
- Cloud SQL for MySQL: Zonal – Micro instance in Americas 2.19 hour ¥3
上から青い線、赤い線、オレンジの線、の順番です。オレンジは最初だけですが、他のは安定していますね。青はIPアドレスの予約、ということなので、利用していなくても課金されてしまう、ということなのでしょうね。赤は、安いストレージ、ということなので、容量を使用している分が、課金されている、ということですね。オレンジはインスタンスなので、停止したから課金されない、ということのようです。微々たる金額ではありますが、使わなくても存在しているだけで請求が発生することがわかりました。IPアドレスは毎日およそ30円なのですね。
まとめ
やはり、書籍やWebで調べることも大事ですが、実際に試してみてよかったです。かなり長くなってしまいましたが、ここまで読んでくださって、ありがとうございます。Cloud SQLのMySQLインスタンスの作り方がわかりました。実際の業務で利用しようと思うと、クライアントのPCから接続する方法とか、他のGoogle App Engineサービスなどから接続する方法など、もうちょっと調べる必要があると思います。とりあえず、試せる環境ができました。