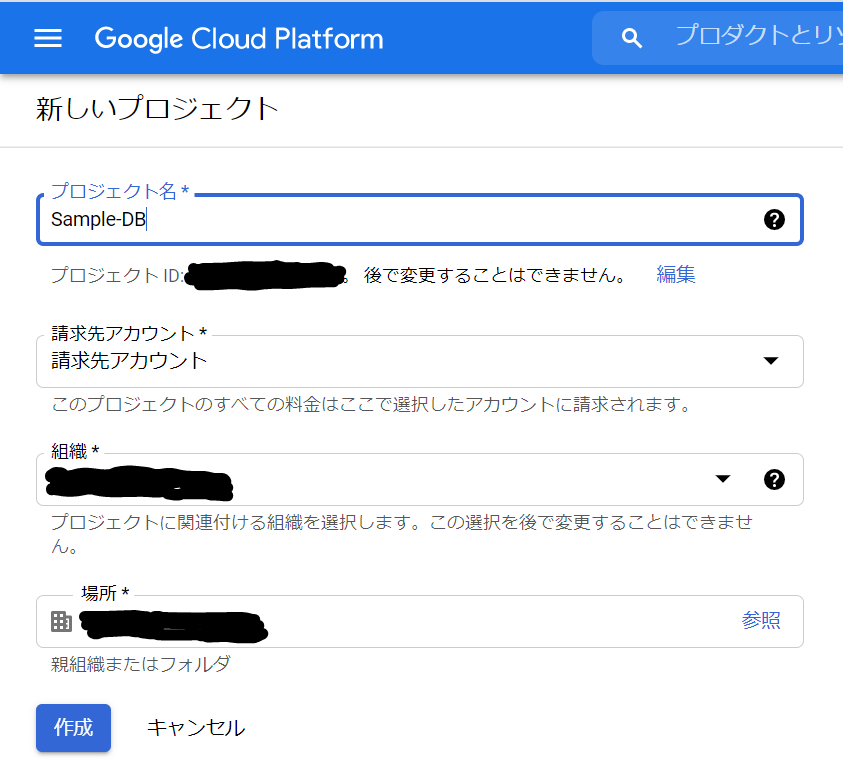
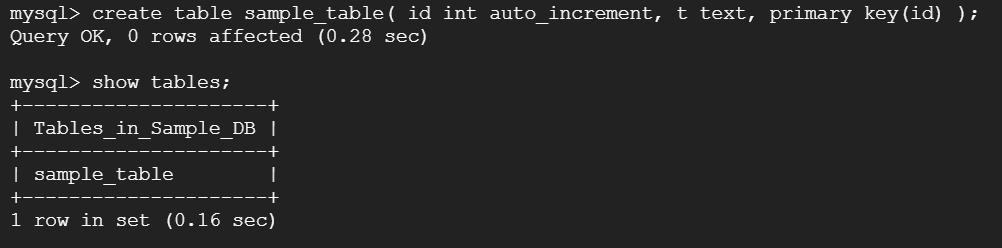
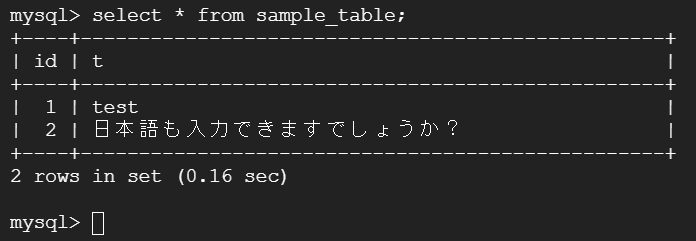
-- テーブルを作成します。POIに意味はありませんが、キーボード上に並んでいて、「ポイ」という感じが気に入っていてテストのときによく使っています。
SQL> create table poi (
2 a number,
3 b number,
4 e number,
5 d number
6 );
表が作成されました。
-- 「C」列を追加し忘れました。よく見ると「E」「D」の列の順番も間違っていました。
SQL> desc poi
名前 NULL? 型
----------------------------------------- -------- ----------------------------
A NUMBER
B NUMBER
E NUMBER
D NUMBER
-- 「C」列を追加します。
SQL> alter table poi add (c number);
表が変更されました。
-- 確認すると、最後に追加されています。
SQL> desc poi
名前 NULL? 型
----------------------------------------- -------- ----------------------------
A NUMBER
B NUMBER
E NUMBER
D NUMBER
C NUMBER
-- 「E」「D」列を「invisible」に設定します。
SQL> alter table poi modify ( e invisible, d invisible );
表が変更されました。
-- 確認すると、確かに「E」「D」列が見えなくなっています。ちなみにこの状態でINSERT INTO POI VALUES ( 1, 2, 3 );を実行すると、見えない列はNULLになりました。
SQL> desc poi
名前 NULL? 型
----------------------------------------- -------- ----------------------------
A NUMBER
B NUMBER
C NUMBER
-- 順番が大事ですので、まずは「D」列を見えるようにします。
SQL> alter table poi modify ( d visible );
表が変更されました。
-- そして、次に「E」列を見えるようにします。
SQL> alter table poi modify ( e visible );
表が変更されました。
-- 確認すると、順番が正しく入れ替わりました。
SQL> desc poi
名前 NULL? 型
----------------------------------------- -------- ----------------------------
A NUMBER
B NUMBER
C NUMBER
D NUMBER
E NUMBER
SQL> insert into poi values ( 1, 2, 3, 4, 5 );
1行が作成されました。
-- INSERT文を実行するときに項目を省略してみましたが、入れ替わった順番どおり値がセットされていました!
SQL> select * from poi;
A B C D E
---------- ---------- ---------- ---------- ----------
1 2 3 4 5
経過: 00:00:00.01
SQL>
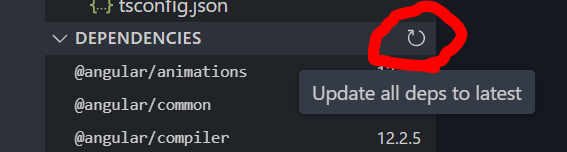
一言でAngularとは何か、というと、ステキなWebアプリを開発するためのフレームワーク、と言ってよいのかな、と、思います。ステキなWebアプリと書きましたが、流行の専門用語ではこれをPWA(Progressive Web Application)と呼んでいて、デスクトップアプリケーションのような体験ができるWebアプリ、ということのようです。これらはGoogleが開発を進めているオープンソースのフロントエンドフレームワークで、半年に一度はメジャーバージョンが更新される、という活発な開発状況です。書籍の数が比較的少ないのは、この頻繁なバージョンアップのせいではないか、ということをぼくは勝手に疑っています。
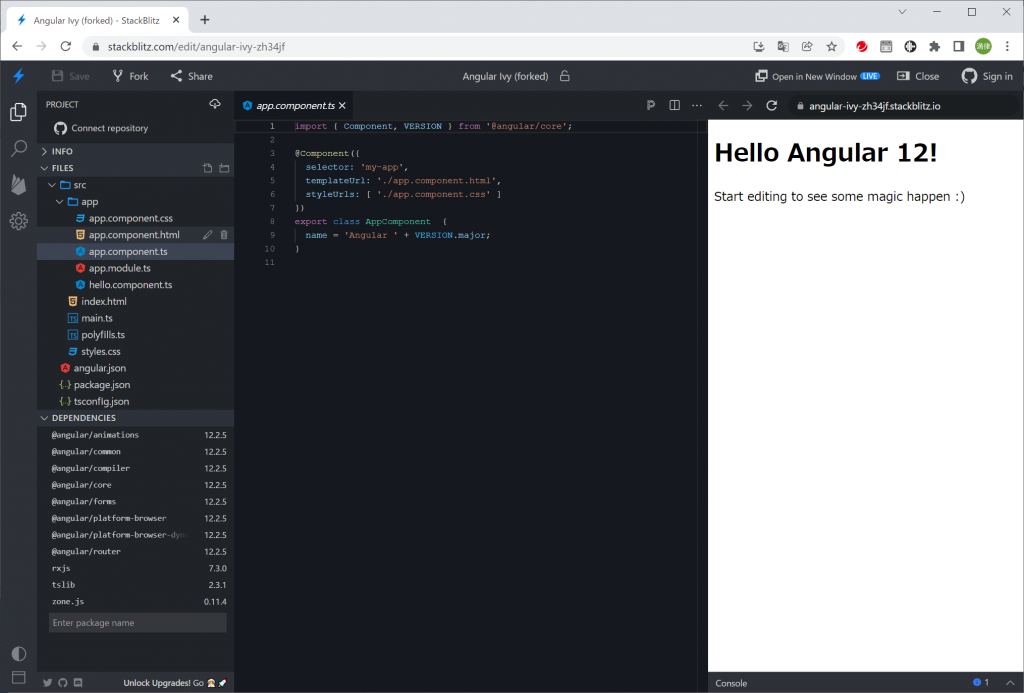
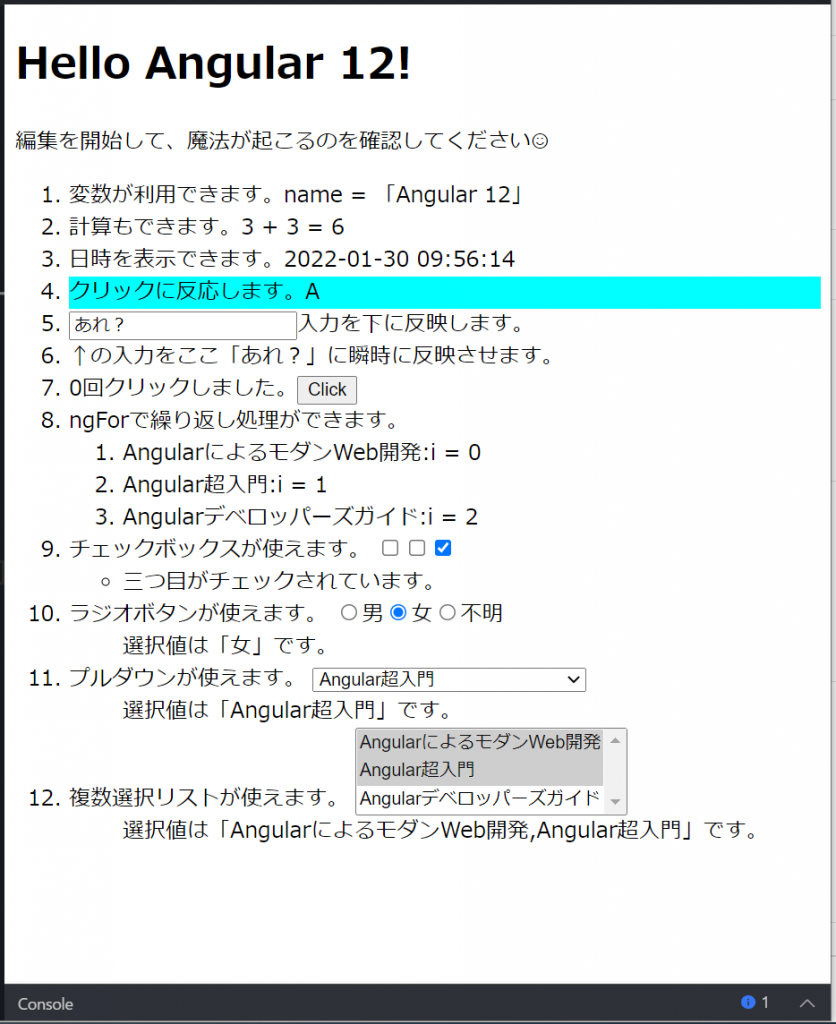
「Start editing to see some magic happen :)」と記載がありますので、ここの部分、さっそく直してみましょう。まずは、日本語使えるのかな、ということでこの部分を日本語にしてみます。左側の「app.component.html」ファイルをクリックして中央に開きます。英語部分を日本語にしてみましょう。
と、いうのも、Angularのホームページのチュートリアルに感動して、これは本格的に取り組まねば、という気持ちになりました。まず、実行できるチュートリアルがすべてWebで完結しているのですよね。Visual Studio CodeのようなIDEが自動的に開始します。先日gitPodでも体験していましたがブラウザだけで開発できるのは素晴らしいですね!そして、コンポーネント指向開発という新しい開発方法もなかなか面白いですね。部品が多くなり過ぎたら再利用が難しくなるかも知れないなぁ、という気持ちになりましたが、もうちょっとやれば、何かつかめるかも知れませんね。
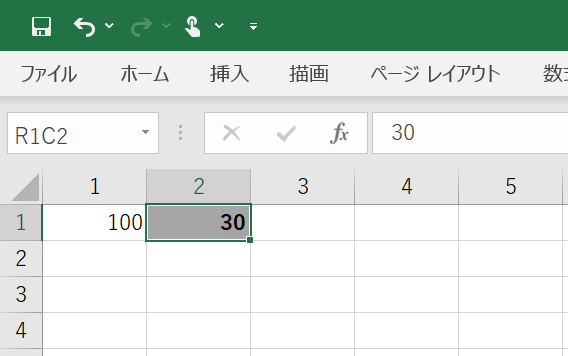
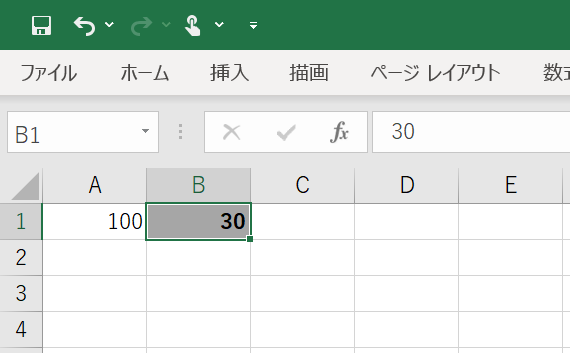
Sub test()
'B1セルの内容がA1セルより小さいとき、B1セルの背景をグレーにしてフォントを太字にする条件付き書式を設定します
With Range("B1").FormatConditions.Add(Type:=xlExpression, Formula1:="=AND($B1<$A$1)")
.Font.Bold = True
.Interior.Color = RGB(166, 166, 166)
End With
End Sub
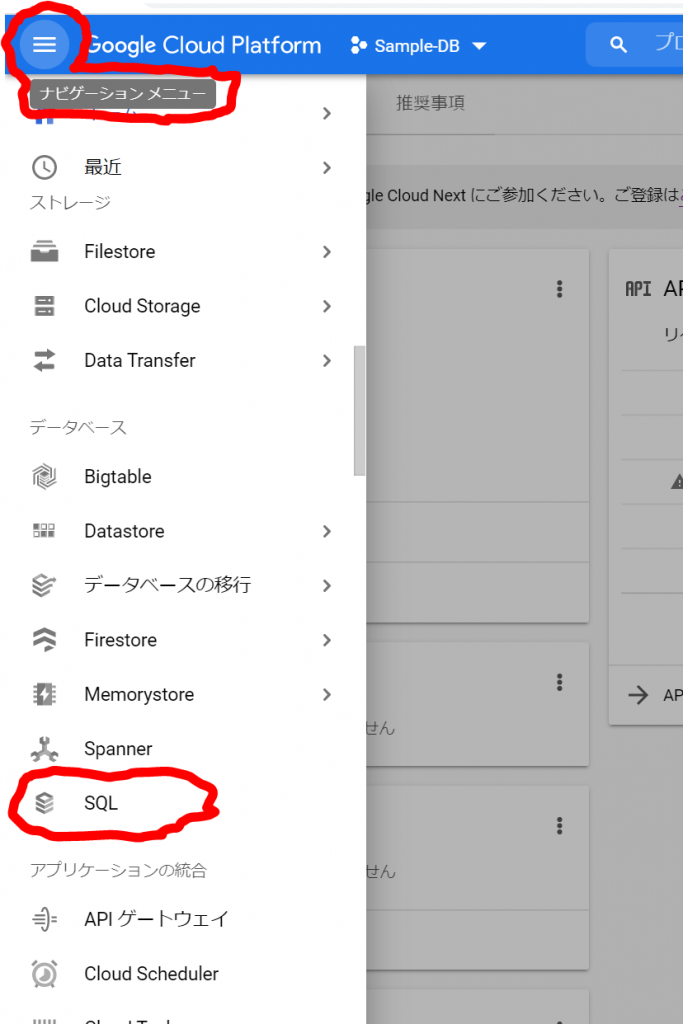
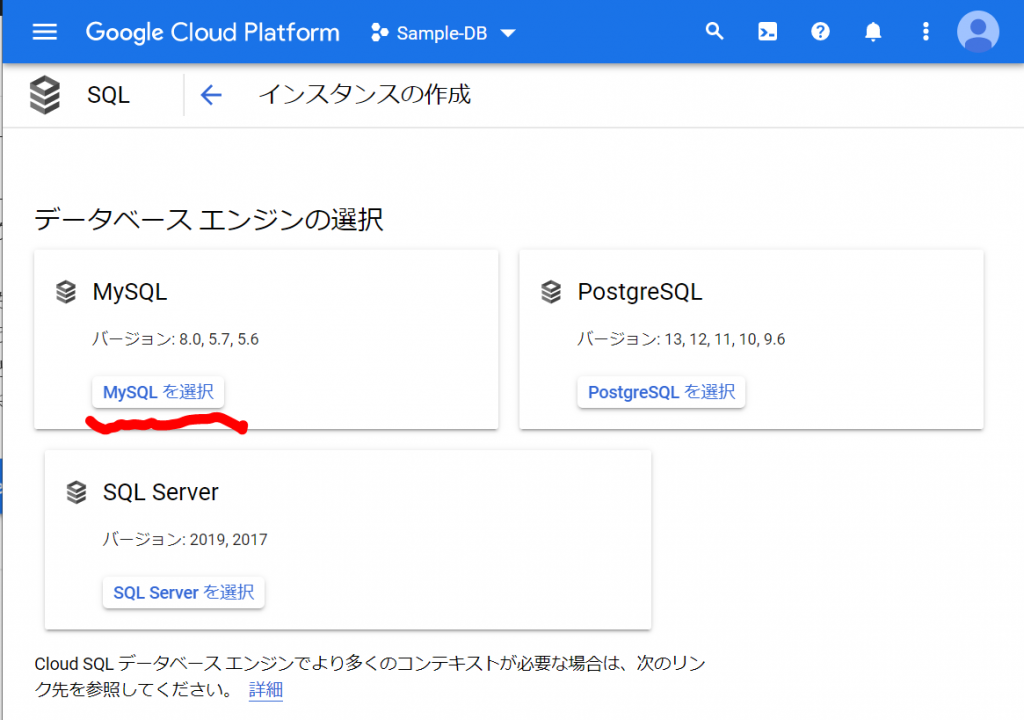
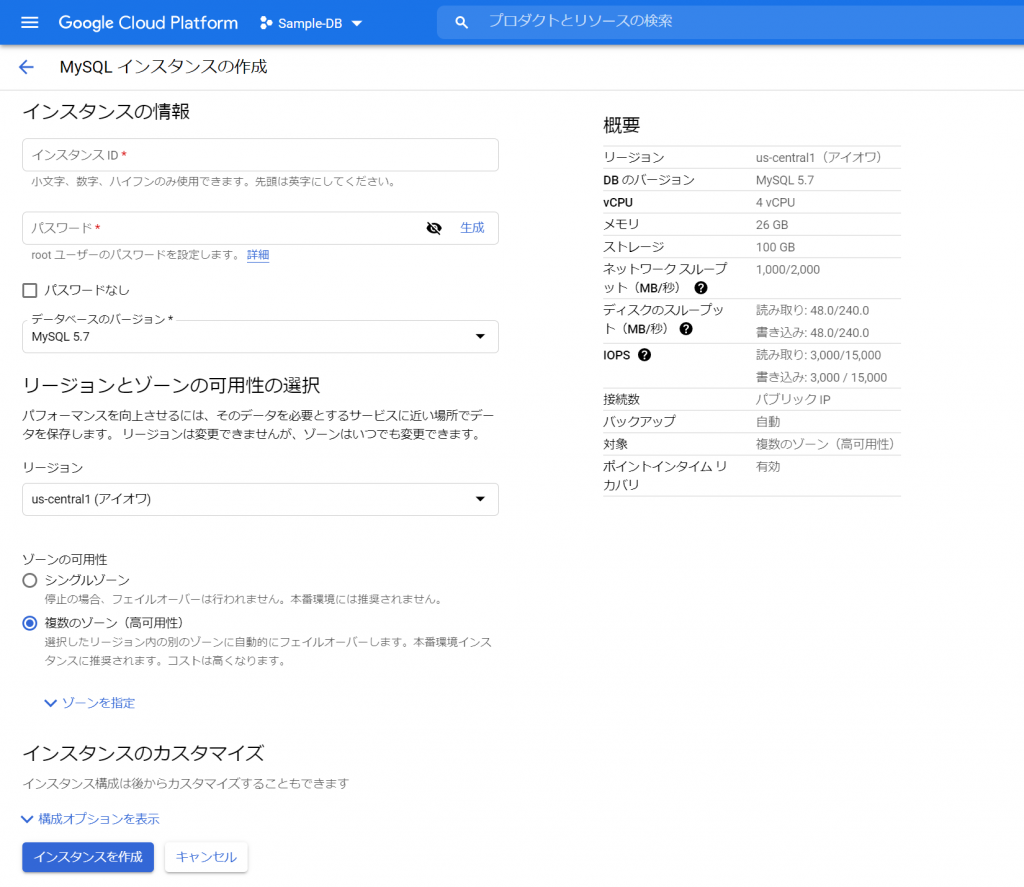
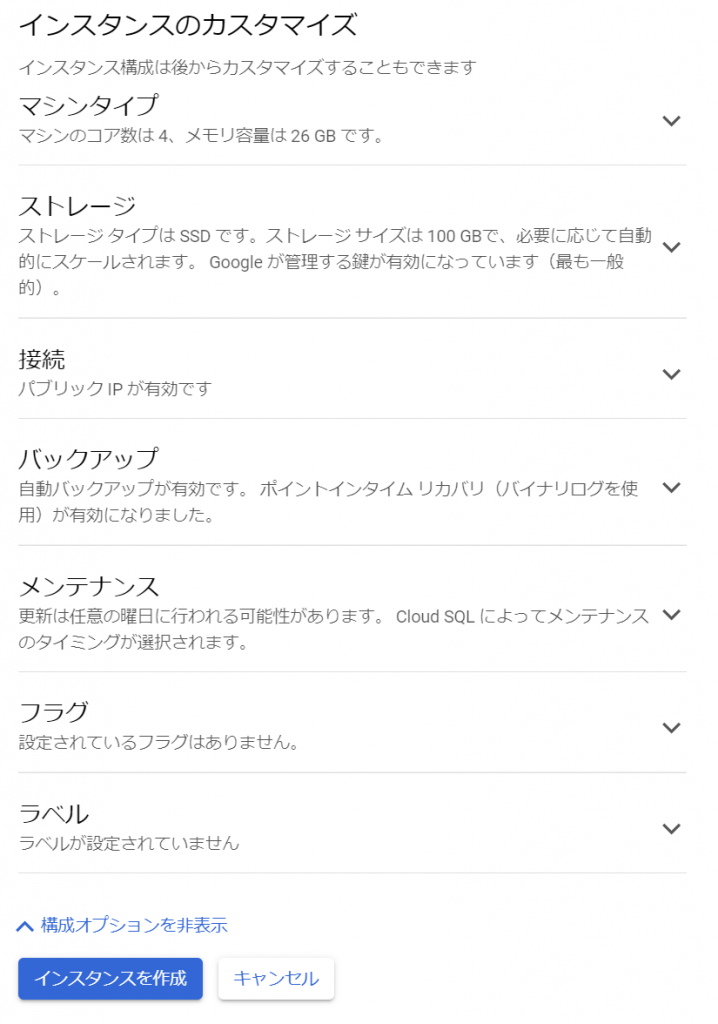
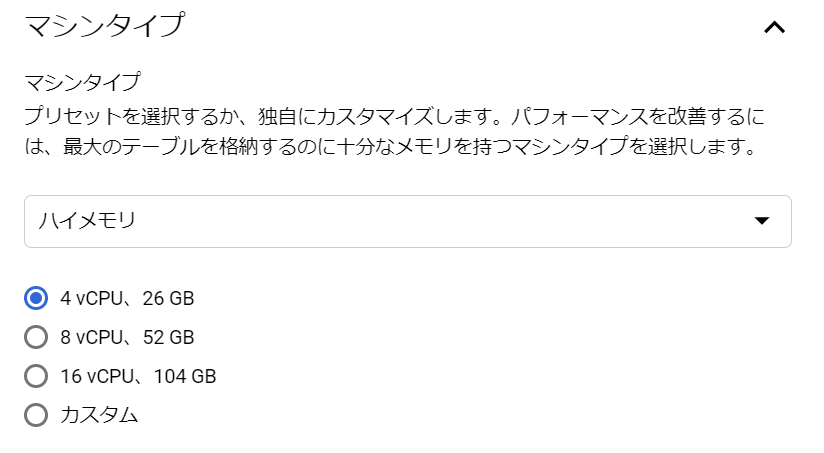
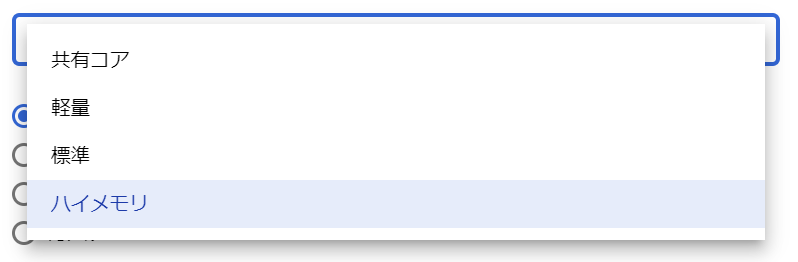
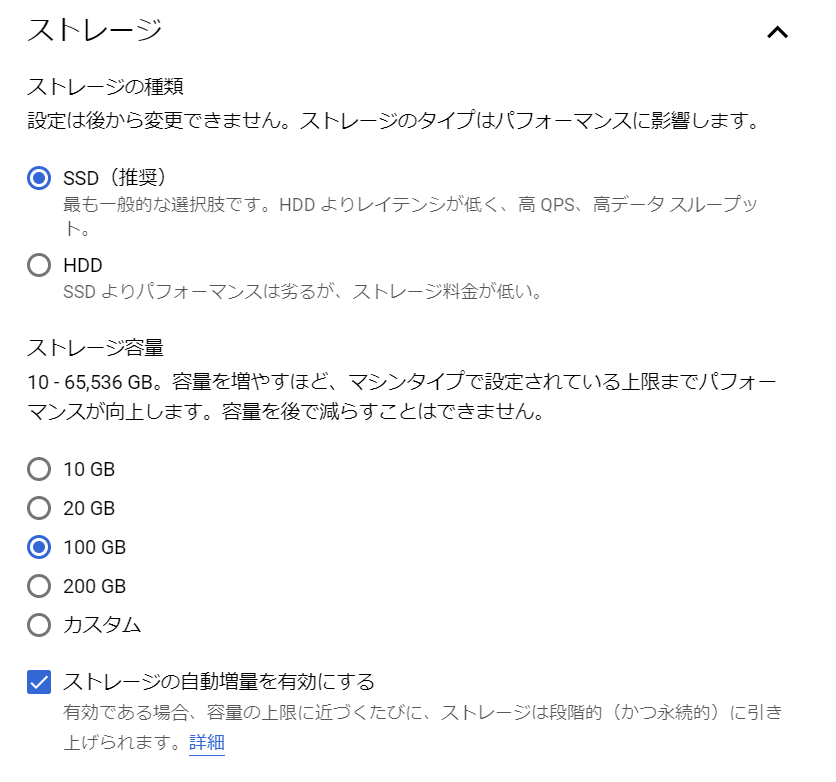
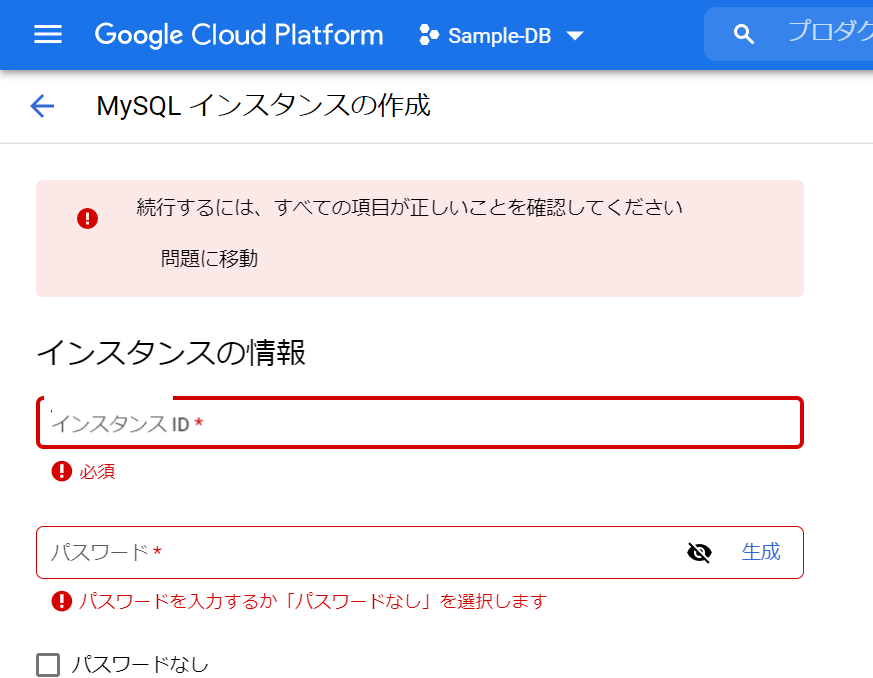
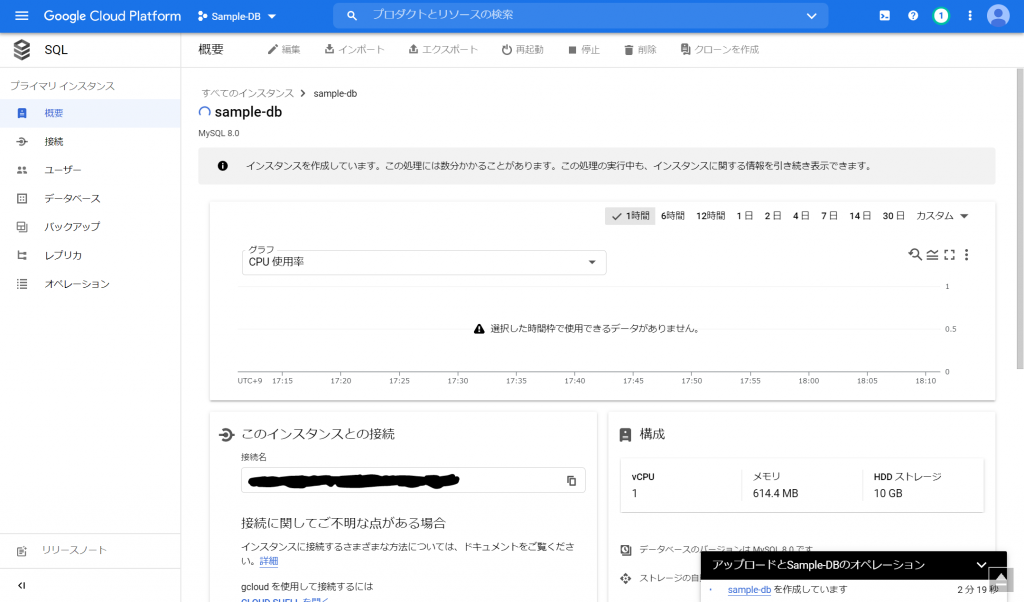
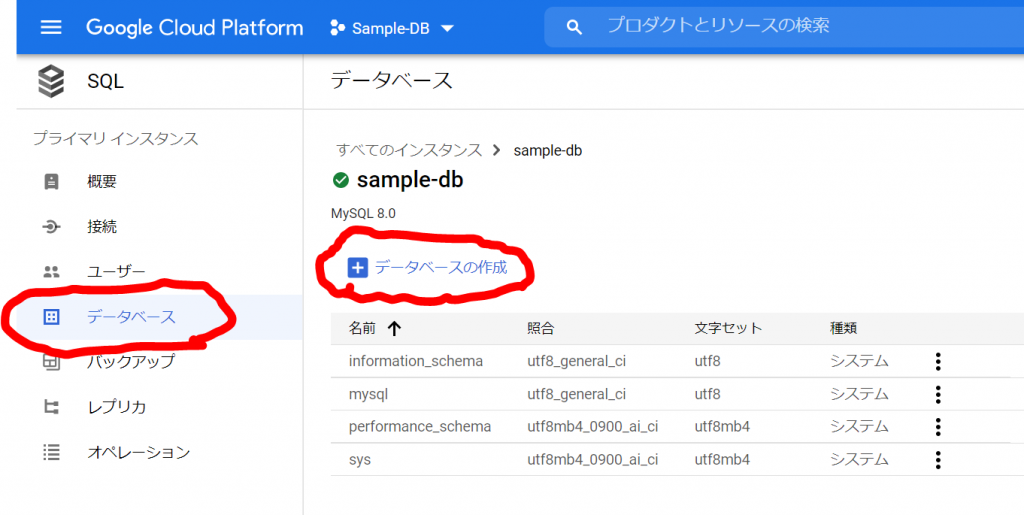
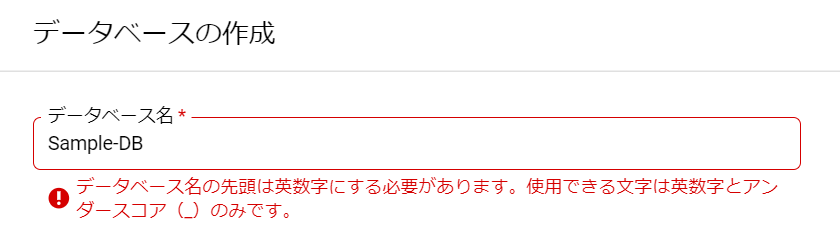
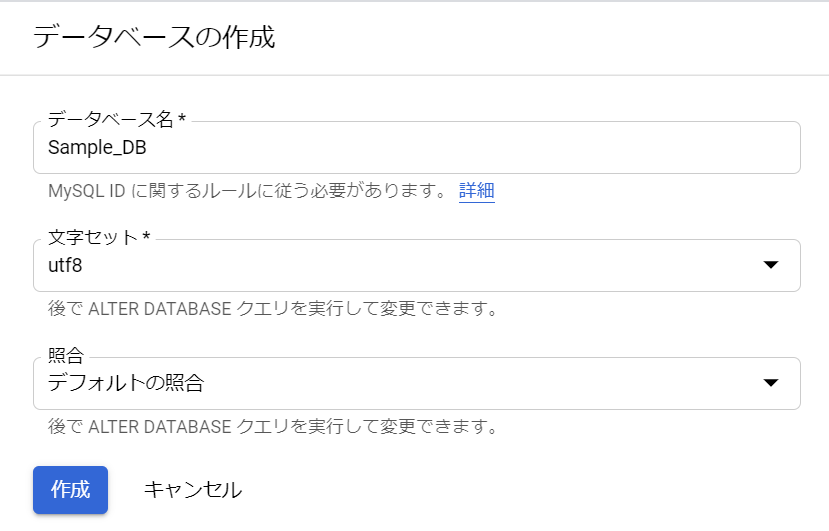
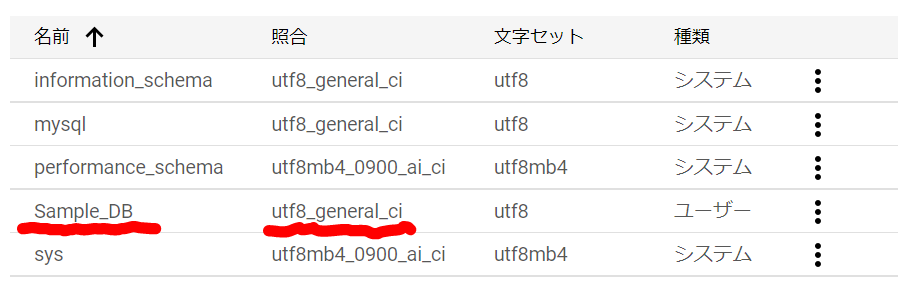
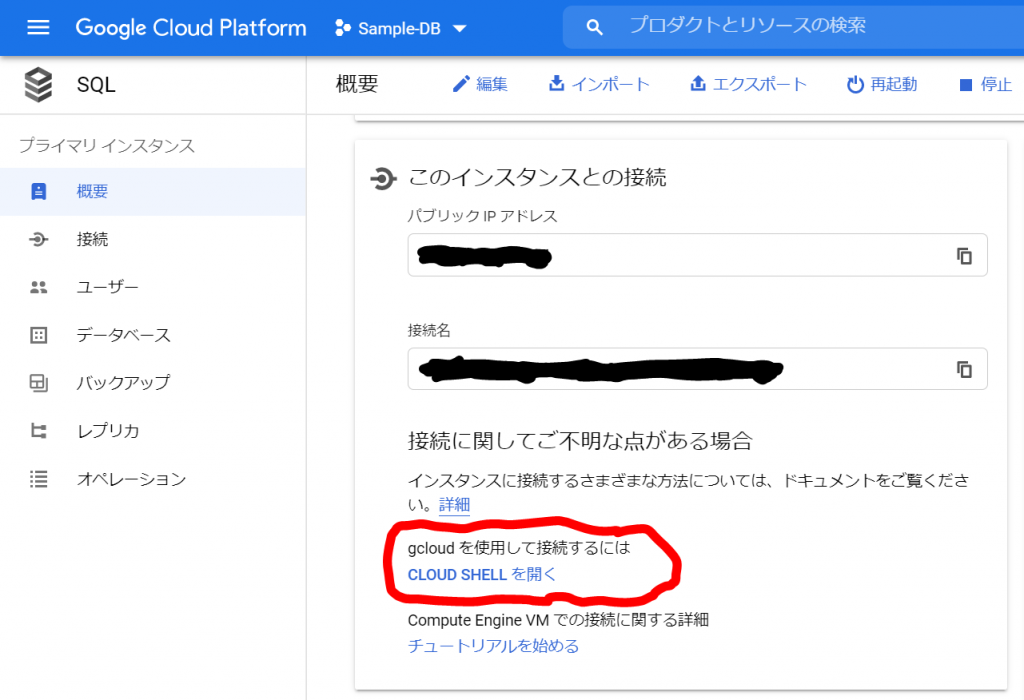
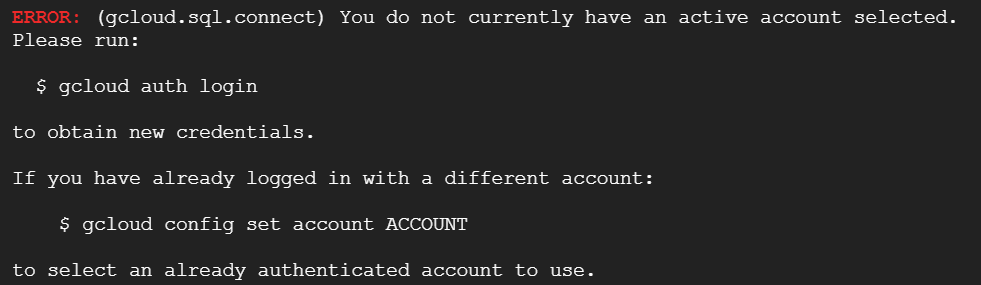
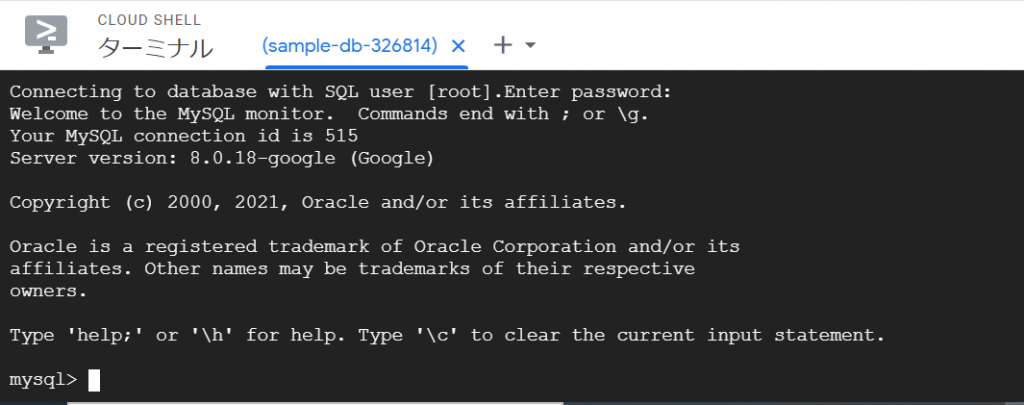
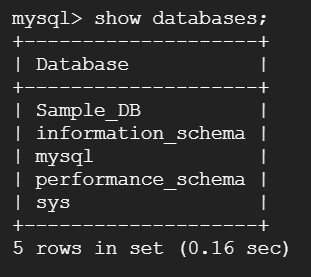
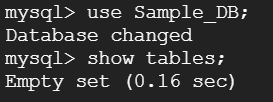
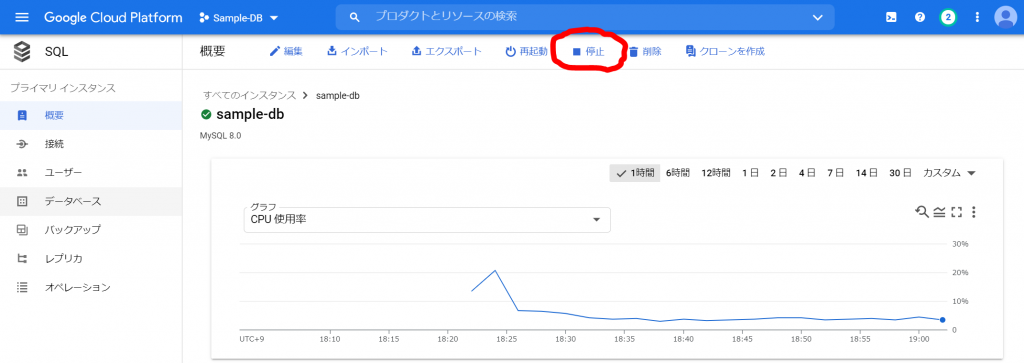
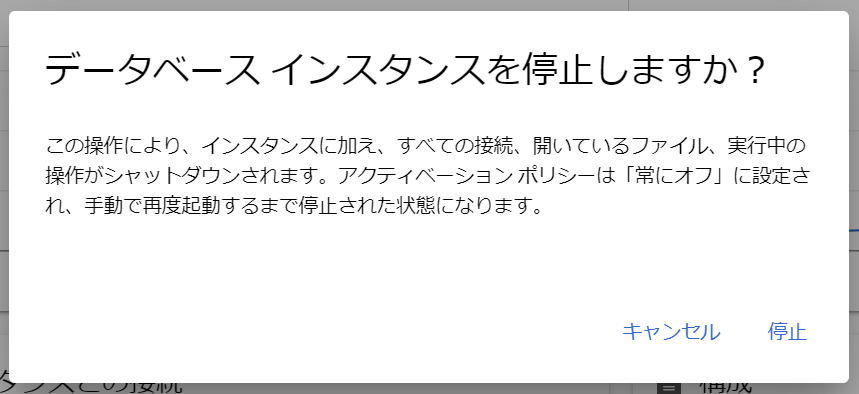
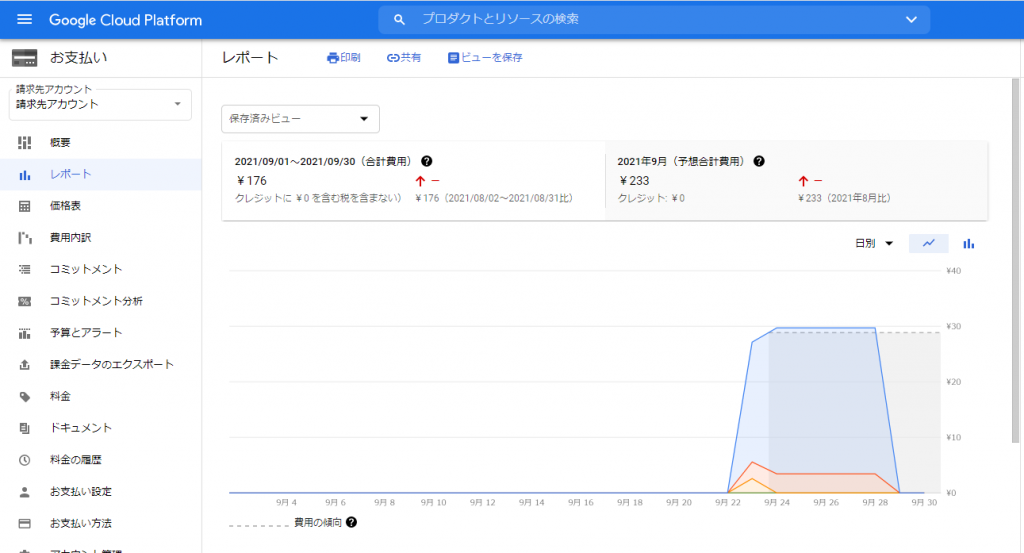
必須入力は、「インスタンスID」と「パスワード」のみですね。今回はお試しで作ってみるだけなので、最小構成にしたいですね。データベースのバージョンは、8.0、5.7、5.6から選べました。おそらく初期値の「5.7」は安定したバージョンなのでしょうね。今回はお試しなので、8.0を選択しておくことにします。インスタンスが作成され、常時存在することになるので、インスタンスを起動している間は使用料がかかります。金額については、概算ですが、Cloud SQL for MySQL の料金で、計算できるようです。リージョンの選択によって若干金額が変わってきます。現時点のアイオワでは、1仮想CPUあたり、1か月で$30.15、1GBあたり、1ヶ月で$5.11です。東京は$39.19、$6.64なので、やはり若干高くなっていますね。業務で利用する場合は、ネットワークの距離の影響もあるので、慎重に選ぶ必要があるかと思いますが、今回は安い方のアイオワで問題ありませんね。そして「ゾーンの可用性」ですがこちらは「シングルゾーン」に変更しましょう。複数のゾーン(高可用性)を選択すると、およそ料金が二倍になります。ま、二台用意しておいて、一台がダメになったとき切り替えてダウンタイムを極小にしよう、という取り組みですから、ま、そうなりますよね。そして、vCPU数が4に、メモリ、26GBもいらないでしょう。こちらは、「構成オプションを表示」を選択することで設定できるようになっていました。
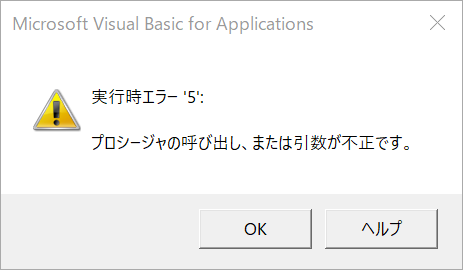
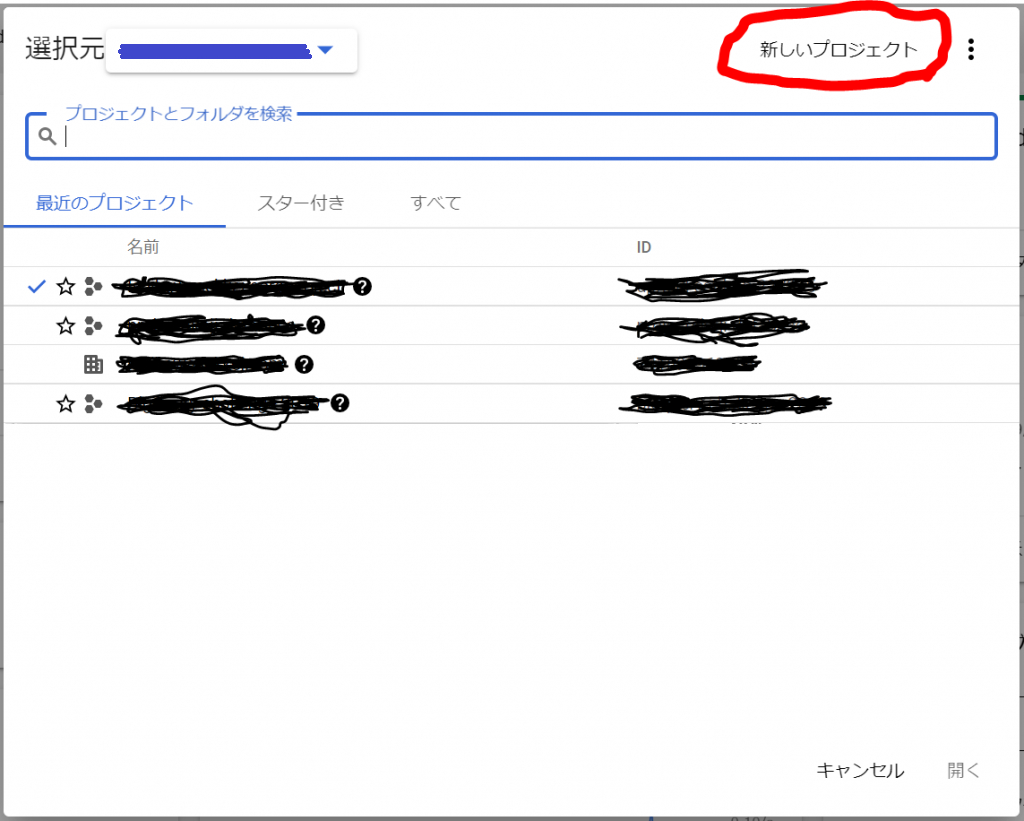
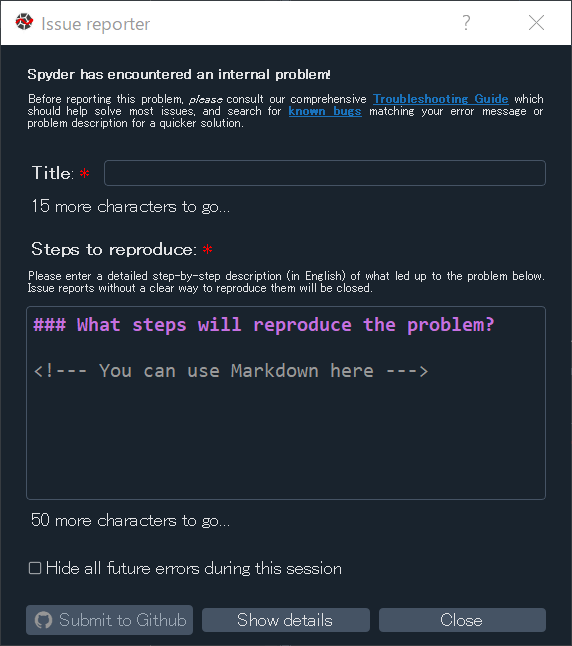
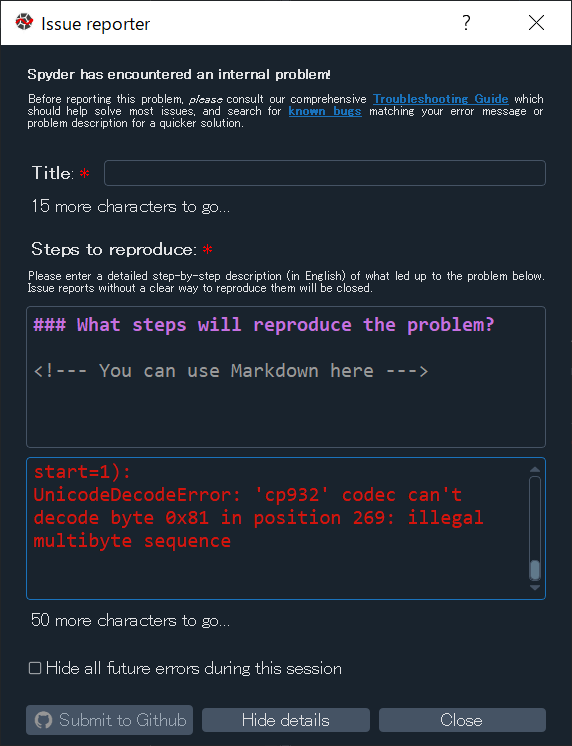
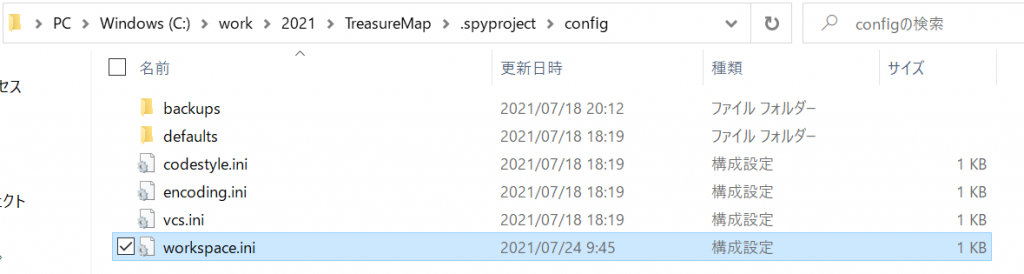
直前に作業していたのは、、、と、記憶をたどると、そうそう、新しくプロジェクトを作成して、そこにドキュメントフォルダをつくって、Sphinxのドキュメントを構築しようとしていたんだった、と、いうことを思い出しました。ということで、その新しいプロジェクトを再度開いてみると、、、おお、エラーか?。。。エラーですね。「Issue reporter」なる画面が起動されました。ふむふむ「Spyder has encountered an internal problem!」ということですね。内部の問題に直面しました、ということなのですが、問題レポートを送ればいいのかな?
Traceback (most recent call last):
File "C:\Users\mitsu\anaconda3\lib\site-packages\spyder\plugins\projects\plugin.py", line 129, in <lambda>
triggered=lambda v: self.open_project())
File "C:\Users\mitsu\anaconda3\lib\site-packages\spyder\plugins\projects\plugin.py", line 402, in open_project
project_type_class = self._load_project_type_class(path)
File "C:\Users\mitsu\anaconda3\lib\site-packages\spyder\plugins\projects\plugin.py", line 813, in _load_project_type_class
config.read(fpath)
File "C:\Users\mitsu\anaconda3\lib\configparser.py", line 697, in read
self._read(fp, filename)
File "C:\Users\mitsu\anaconda3\lib\configparser.py", line 1017, in _read
for lineno, line in enumerate(fp, start=1):
UnicodeDecodeError: 'cp932' codec can't decode byte 0x81 in position 269: illegal multibyte sequence
Python 3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.22.0 -- An enhanced Interactive Python.
In [1]: import sys, locale
In [2]: locale.getpreferredencoding()
Out[2]: 'cp932'
In [3]: my_file = open("dummy","w")
In [4]: type(my_file)
Out[4]: _io.TextIOWrapper
In [5]: my_file.encoding
Out[5]: 'cp932'
In [6]: sys.stdout.isatty()
Out[6]: False
In [7]: sys.stdout.encoding
Out[7]: 'UTF-8'
In [8]: sys.stdin.isatty()
Out[8]: False
In [9]: sys.stdin.encoding
Out[9]: 'cp932'
In [10]: sys.stderr.isatty()
Out[10]: False
In [11]: sys.stderr.encoding
Out[11]: 'UTF-8'
In [12]: sys.getdefaultencoding()
Out[12]: 'utf-8'
In [13]: sys.getfilesystemencoding()
Out[13]: 'utf-8'
In [14]: my_file.close()
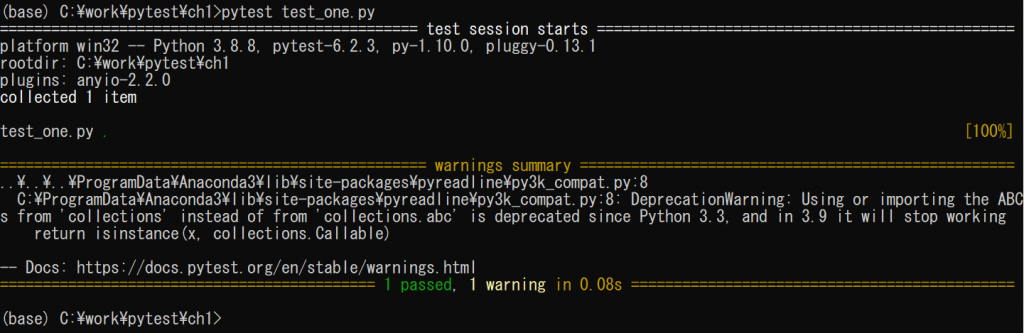
(base) C:\work\pytest\ch1>pytest test_one.py
================================================= test session starts =================================================
platform win32 -- Python 3.8.8, pytest-6.2.3, py-1.10.0, pluggy-0.13.1
rootdir: C:\work\pytest\ch1
plugins: anyio-2.2.0
collected 1 item
test_one.py . [100%]
================================================== warnings summary ===================================================
..\..\..\ProgramData\Anaconda3\lib\site-packages\pyreadline\py3k_compat.py:8
C:\ProgramData\Anaconda3\lib\site-packages\pyreadline\py3k_compat.py:8: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
return isinstance(x, collections.Callable)
-- Docs: https://docs.pytest.org/en/stable/warnings.html
============================================ 1 passed, 1 warning in 0.08s =============================================
(base) C:\work\pytest\ch1>
インストールできたら、実行します。黒いコマンドラインがフルスクリーンで登場します。pytestを実行してみましたが、コマンドが存在しない(command not found)、と、エラーになります。pytestを使えるようにするためには、インストールが必要ですね。pipコマンド「pip install pytest」で簡単に実行できるようになりました。
$ pytest
pytest: command not found
$ pip install pytest
Defaulting to user installation because normal site-packages is not writeable
Collecting pytest
Downloading pytest-6.2.4-py3-none-any.whl (280 kB)
|████████████████████████████████| 280 kB 4.0 MB/s
Requirement already satisfied: packaging in /private/var/containers/Bundle/Application/10B03820-2240-4A08-AA93-CE205988D553/a-Shell.app/Library/lib/python3.9/site-packages (from pytest) (20.9)
Requirement already satisfied: attrs>=19.2.0 in /private/var/containers/Bundle/Application/10B03820-2240-4A08-AA93-CE205988D553/a-Shell.app/Library/lib/
python3.9/site-packages (from pytest) (20.3.0)
Requirement already satisfied: toml in /private/var/containers/Bundle/Application/10B03820-2240-4A08-AA93-CE205988D553/a-Shell.app/Library/lib/python3.9/site-packages (from pytest) (0.10.2)
Collecting py>=1.8.2
Downloading py-1.10.0-py2.py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 10.5 MB/s
Collecting iniconfig
Downloading iniconfig-1.1.1-py2.py3-none-any.whl (5.0 kB)
Collecting pluggy<1.0.0a1,>=0.12
Downloading pluggy-0.13.1-py2.py3-none-any.whl (18 kB)
Requirement already satisfied: pyparsing>=2.0.2 in /private/var/containers/Bundle/Application/10B03820-2240-4A08-AA93-CE205988D553/a-Shell.app/Library/lib/python3.9/site-packages (from packaging->pytest) (2.4.7)
Installing collected packages: py, pluggy, iniconfig, pytest
Successfully installed iniconfig-1.1.1 pluggy-0.13.1 py-1.10.0 pytest-6.2.4