先日の続きです。
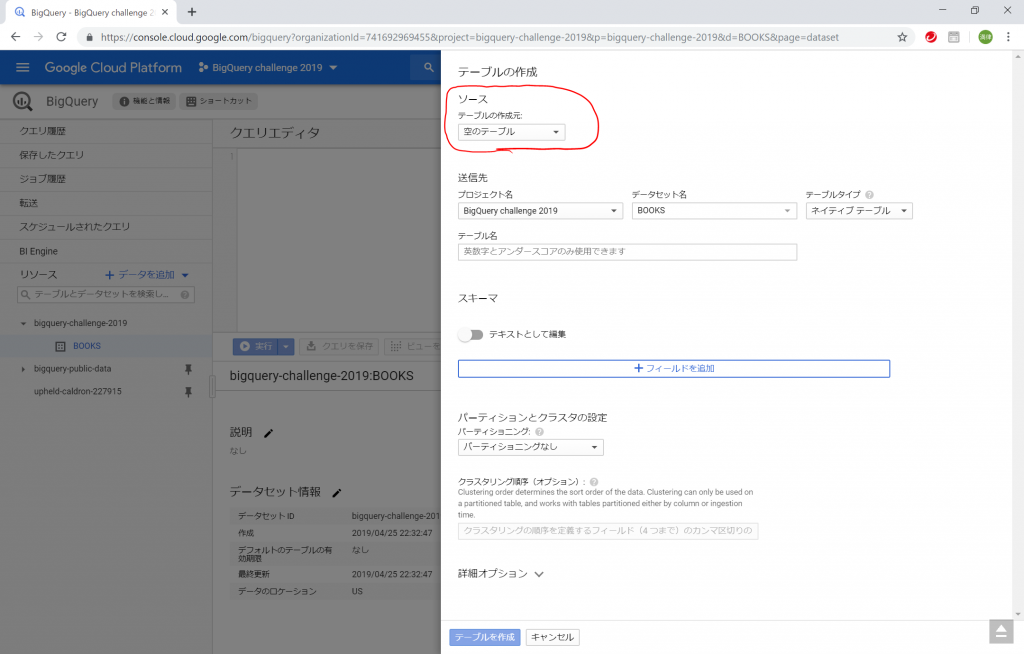
空のテーブルはできましたが、データの入れ方がわかりません。RDBならINSERT文ですよね、ということでお試しでINSERT文を書いてみました。
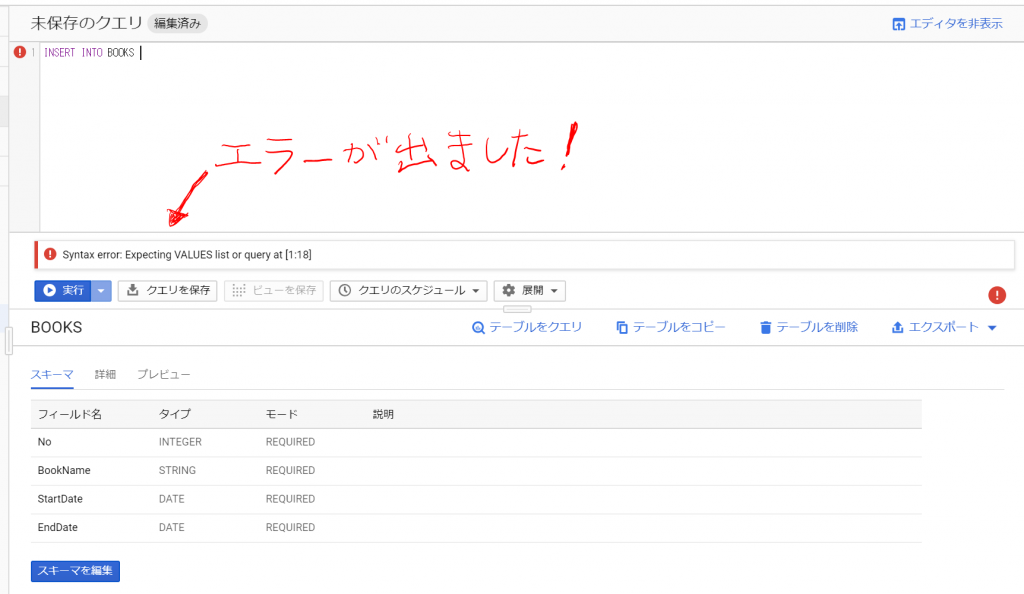
何と、エラーが出ました。「VALUES」のリストかクエリが想定されているんだけど、違いますよ~、と、言われていますね。完全に当てずっぽうで書いてみたのですけど、行けましたねぇ。続きを書いてみます。文字列の表現はシングルクォーテーションでいいのか、日付はどうやって表現するのか分からないけど、とりあえずの形で「INSERT INTO BOOKS VALUES (1, ‘CASEツール ‘, 1989-11-01, 1999-11-01);」を書いてみたところ、やはりエラーが。。。「Table name “BOOKS” cannot be resolved: dataset name is missing.」ということで、データセットの名前が必要ということですね。。。いやいや、これはいつ終わるかわからないパターンですよ。
と、いうことでまじめにやりましょう。こういう時はマニュアルを参照します。右上の方にアイコンがありましたよ!
ヘルプをクリックしたら、「人気の記事」一覧が表示されましたので、その中の「BigQuery」を選んでみました。すると、いろいろ書いてありますが、、、「よく参照されるトピック」の中に、「BigQueryへのデータの読み込み」がありました。ポチリと押してみましたら、書いてありましたねぇ。データは次の方法で読み込むことができます、、、
- Cloud Storage から
- Google アド マネージャーや Google 広告などの他の Google サービスから
- 読み取り可能なデータソース(ローカルマシンなど)から
- ストリーミング挿入を使用してレコードを個別に挿入する
- DML ステートメントを使用して一括挿入を行う
- Cloud Dataflow パイプラインの BigQuery I/O 変換を使用して BigQuery にデータを書き込む
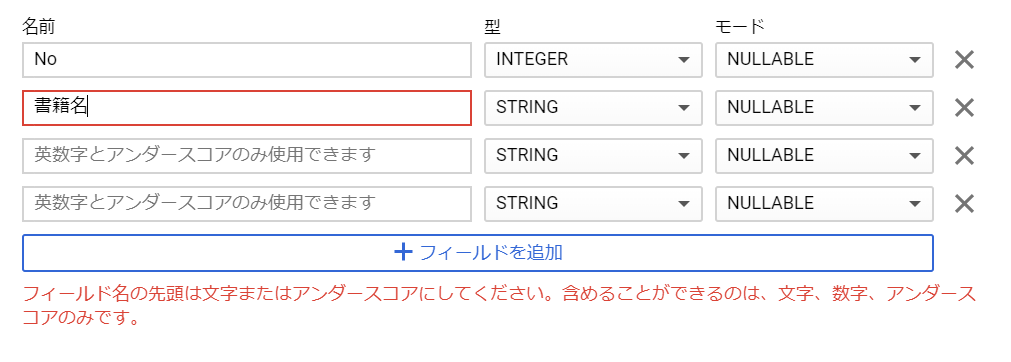
ということで、今回は5番目のDMLステートメントでチャレンジしている、ということですね。で、マニュアルをよく読んでみると、INSERT文はカラムを指定する必要があるということで、気を取り直して実行してみますが、、、今度は、「Syntax error: Unexpected keyword NO at [1:26]」というエラーメッセージ。どうやら、カラム名に「No」を使っていたのがいけないのでしょうか。イライラしますねぇ♪
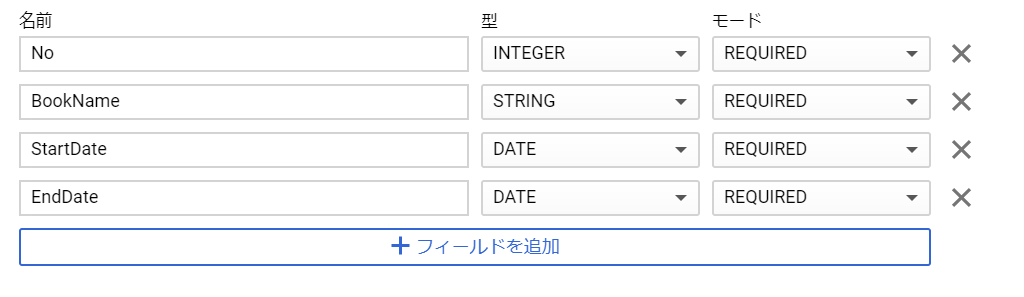
はい、気を取り直して、No→BookNoに変更してテーブルを作り直します。今度は前回の経験をもとに、スキーマをテキストとして編集で作成してみました。カンマ区切りか、JSON形式で作成できるようです。
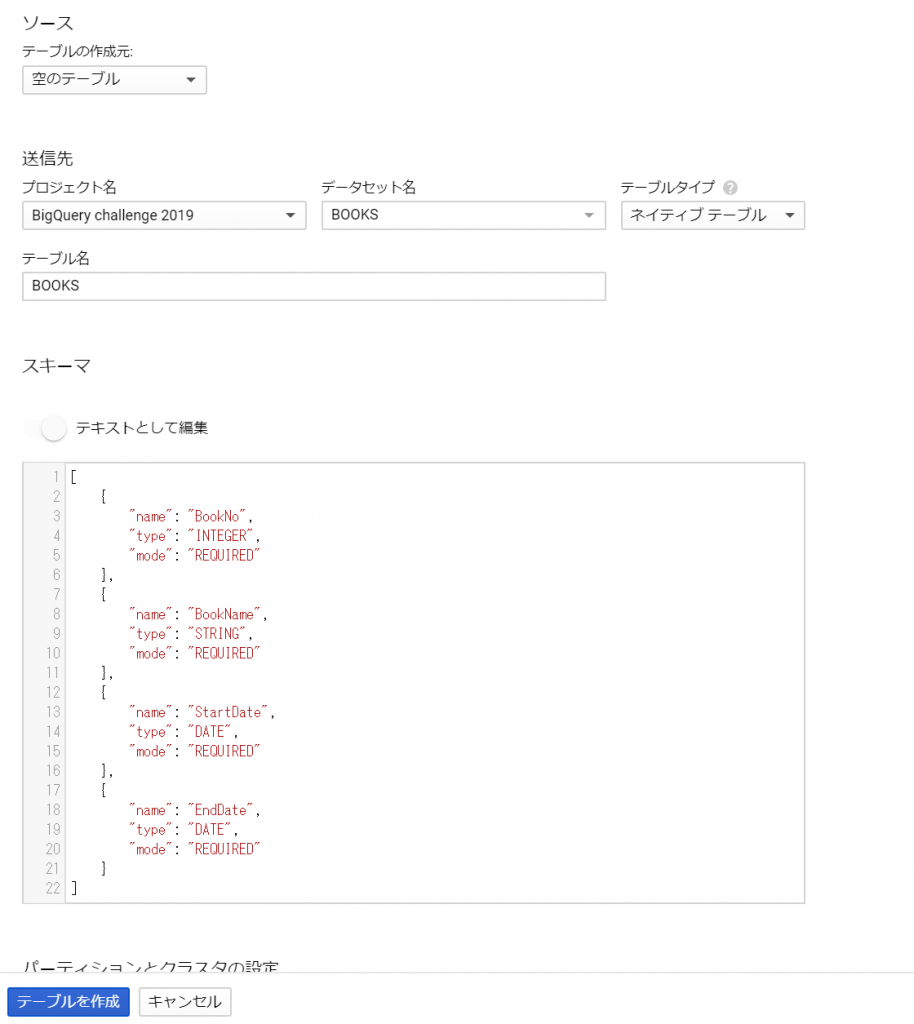
さあ、気を取り直してINSERT文作成の続きです。日付の指定方法が分かりませんでしたが、文字列としておけば問題なさそうです。なんとか成功しそうです!どやっ!?
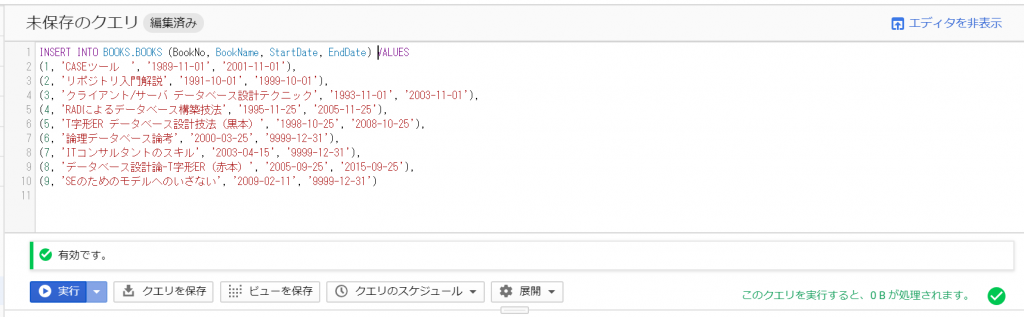
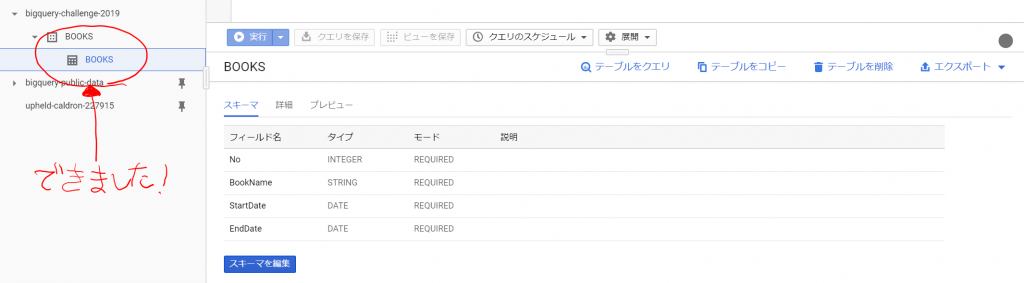
成功しました!

「テーブルに移動」して「プレビュー」を選択すると、データが入っていました。数行でも並列で投入されるのでしょうか、順番はバラバラになっていました。
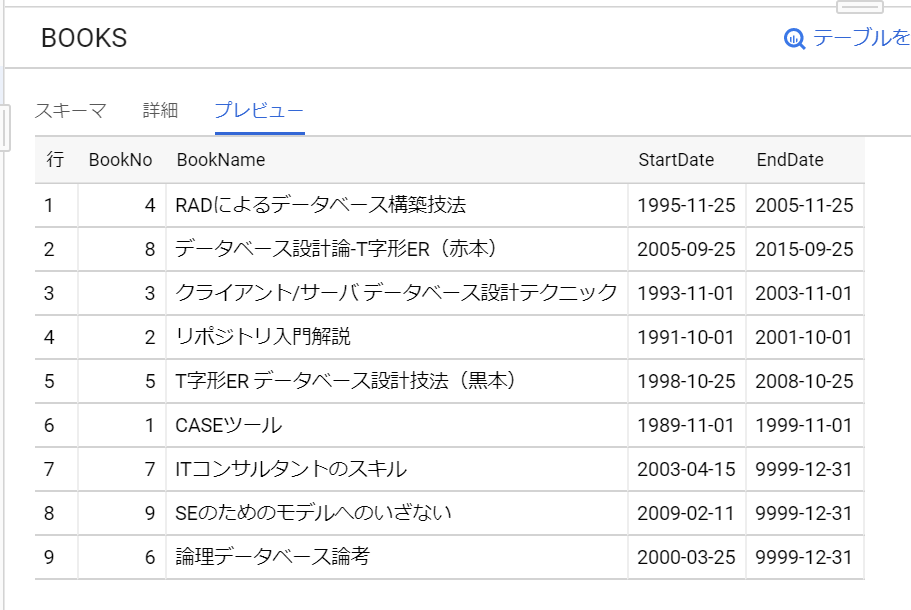
それにしても、項目に予約語は使えないなら、作るときに教えてくれればいいのにねぇ。日本語の項目が作れないのも不親切な教え方でしたけど、テーブル作成上の注意点はこのあたりでしょうか。データ作成時の注意点は項目の指定は省略できないという点でした。で、やっと最初に話したかった話題の準備ができましたが、ちょっと長くなってきたので、次のエントリーとします。