
今日も見に来てくださって、ありがとうございます。
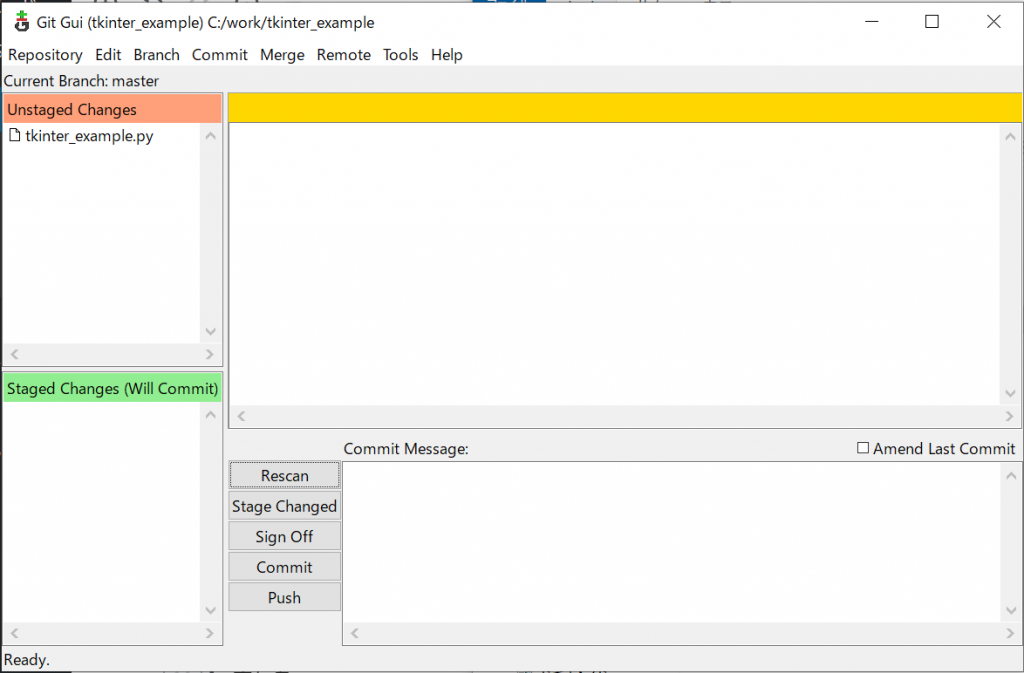
今回は、tkinterで用意されているダイアログを見てみましょう。英語でダイアログとは、会話のことで、コンピューター用語としては、メッセージを出力するポップアップ画面のことを言います。ここでは、情報を出力して、ユーザーにアクションを促すダイアログを紹介します。ボタンがひとつのダイアログは3種類、ボタンがふたつのダイアログは4種類、ボタンが三つのタイプはひとつ用意されています。ダイアログを表示するためのメニュー画面を作ってみました。こんな感じです。
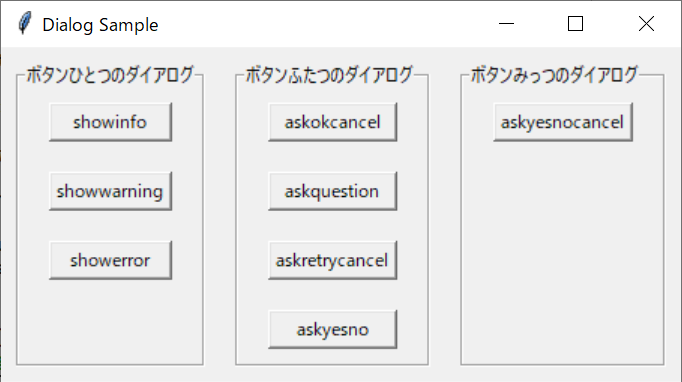
それぞれボタンを押すと以下のダイアログが開きます。ダイアログのボタンを押すと、コンソールに戻り値を出力します。
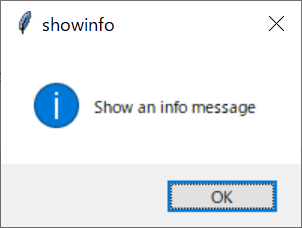
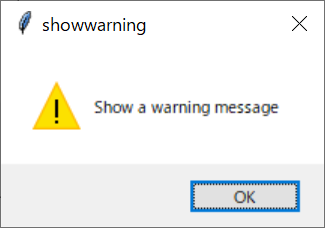
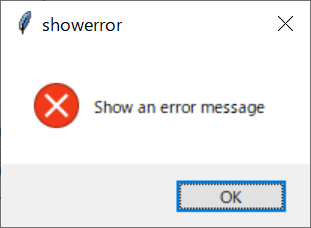
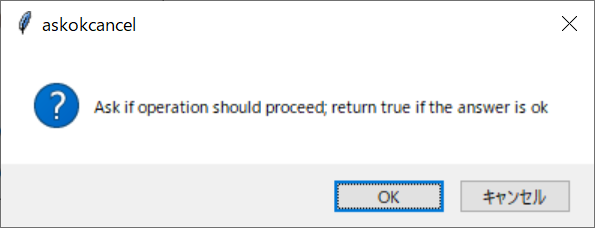
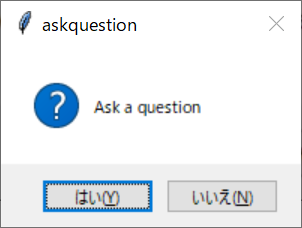
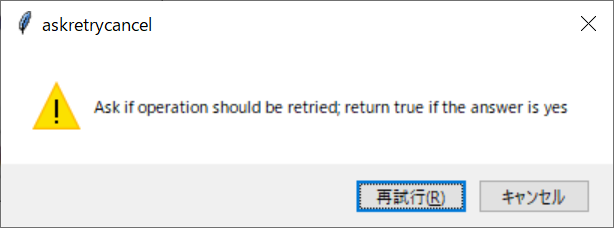
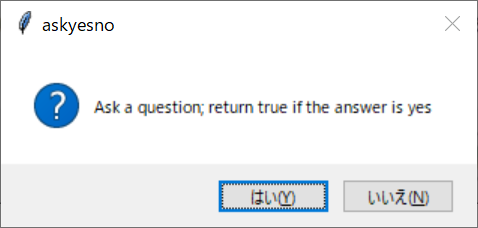
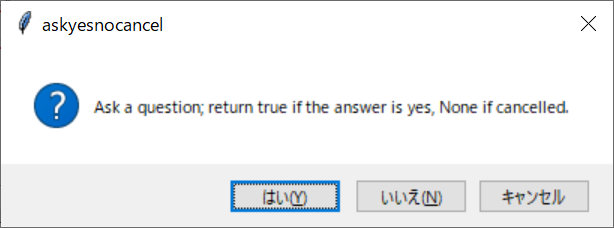
上記の画面を出力するスクリプトは、以下の通りです。
import tkinter as tk
import tkinter.messagebox as mb
class DialogSample(tk.Tk):
def create_button(self, group, dialog):
def command():
ret = dialog(master=self, title=dialog.__name__, message=dialog.__doc__)
print(ret)
b = tk.Button(group, text=dialog.__name__, command=command)
b.pack(padx=20, pady=10, fill=tk.BOTH)
def __init__(self):
super().__init__()
self.title("Dialog Sample")
self.g1 = tk.LabelFrame(self, text="ボタンひとつのダイアログ")
self.g1.pack(padx=10, pady=10,side=tk.LEFT, fill=tk.BOTH)
self.create_button(self.g1, mb.showinfo)
self.create_button(self.g1, mb.showwarning)
self.create_button(self.g1, mb.showerror)
self.g2 = tk.LabelFrame(self, text="ボタンふたつのダイアログ")
self.g2.pack(padx=10, pady=10, side=tk.LEFT, fill=tk.BOTH)
self.create_button(self.g2, mb.askokcancel)
self.create_button(self.g2, mb.askquestion)
self.create_button(self.g2, mb.askretrycancel)
self.create_button(self.g2, mb.askyesno)
self.g3 = tk.LabelFrame(self, text="ボタンみっつのダイアログ")
self.g3.pack(padx=10, pady=10, side=tk.RIGHT, fill=tk.BOTH)
self.create_button(self.g3, mb.askyesnocancel)
if __name__ == "__main__":
d = DialogSample()
d.mainloop()
ダイアログを実行すると値が帰ってきます。ボタンがひとつのダイアログは、okの文字列が、ボタンがふたつのダイアログはaskquestionはyes/noで、それ以外はTrue/Falseが戻されました。ボタンがみっつのダイアログはなんと、それぞれのボタンでTrue/False/Noneを戻してきました。まとめると以下の表のようになります。
| ダイアログ | ボタン1 | ボタン2 | ボタン3 | 戻り値1 | 戻り値2 | 戻り値3 | ×ボタン |
| showinfo | OK | ー | ー | ok | ー | ー | ok |
| showwarning | OK | ー | ー | ok | ー | ー | ok |
| showerror | OK | ー | ー | ok | ー | ー | ok |
| askokcancel | OK | キャンセル | ー | True | False | ー | False |
| askquestion | はい | いいえ | ー | yes | no | ー | 使用不可 |
| askretrycancel | 再試行(R) | キャンセル | ー | True | False | ー | False |
| askyesno | はい(Y) | いいえ(N) | ー | True | False | ー | 使用不可 |
| askyesnocancel | はい(Y) | いいえ(N) | キャンセル | True | False | None | None |
面白いなぁ、と、思ったのは、戻り値の違いです。True、False、Noneはそうかな、という気持ちになるのですけど、yes、no、okは微妙な気持になります。ま、okはチェックしないだろうから問題ないですけど、yes、noは、どちらか絶対答えてほしいという気持ちの表れなのかな。そして、askquestionとaskyesnoは絶対混乱すると思いますよね。(笑)
【追記】
tkinterのmessagebox.pyのソースコードを見ていたら、ABORTRETRYIGNOREという未使用の変数が定義されていました。本家のTkで使えるから定義だけはしておいたのでしょうか。messagebox.pyでダイアログまで作っておいてくれればいいのにね。と、いうことで作ってみました。
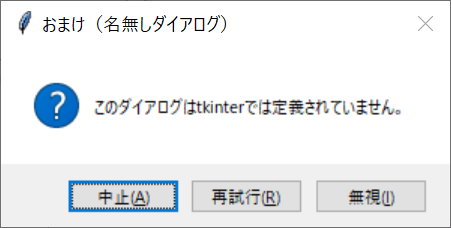
戻り値は、それぞれabort、retry、ignoreとなっていました。
tkinterでダイアログは未定義なので、一覧を修正するのはどうかなぁ、と思ったので、どうやって作ったのか、ソースだけ載せておきます。
def create_abortretryignore_button(self, group):
def command():
ret = mb._show(master=self,
title="おまけ(名無しダイアログ)",
message="このダイアログはtkinterでは定義されていません。",
icon=mb.QUESTION,
type=mb.ABORTRETRYIGNORE)
print(ret)
b = tk.Button(group, text=mb.ABORTRETRYIGNORE, command=command)
b.pack(padx=20, pady=10, fill=tk.BOTH)