

今日も見にきてくださって、ありがとうございます。がんばって更新していきます。
ずっとデータベースの論理設計の勉強会に参加しているのですけど、そちらでしばらくPythonの勉強会をすることになりました。メンバーのなかでは適任者ということで講師に任命されまして、それで先日、第一回目が開催されました。その講習の中でぼくが「Pythonでは、すべてがオブジェクトとして管理されています。」と説明してから、ふと、class作成後、class変更したら、以前のclassとは異なるオブジェクトになっているのだろうか、ということが自分でも気になったので、確認してみました。でも、このタイトルだと、なんのこっちゃ、という感じですねぇ♪
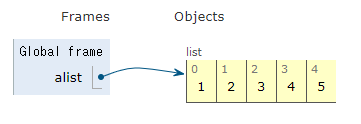
まず、オブジェクトとはこんな感じのモノです、というイメージがわかりやすいように、listを作成してみます。ご覧のとおり、typeはlistになり、オブジェクトとして管理するためにidが採番されています。
>>> alist = [1,2,3,4,5] >>> type(alist) <class 'list'> >>> id(alist) 3005538914888 >>>
にてイメージ化。
ちなみに、この中で使われている「1」などの数値もオブジェクトとして管理されています。調べていて面白かったのは、-5~256の範囲の数値はintのオブジェクトとしてあらかじめキャッシュされて使いまわされているそうです。この点は処理系によって実装は異なるのでしょうけど、ぼくの環境では以下のように確かに使いまわされているのが確認できました。
>>> type(1) <class 'int'> >>> id(1) 140729051148544 >>> id(alist[0]) 140729051148544 >>> id(2) 140729051148576 >>> id(1+1) 140729051148576 >>> id(alist[1]) 140729051148576
では、本題のclassを定義して確認してみます。以下のようなスクリプトを実行してみます。poiクラスを作成してidを確認してから、内容を少し変更したpoiクラスを再作成してもう一度idを確認してみます。
class poi: pass print(type(poi)) print(id(poi)) class poi: a = 1 print(type(poi)) print(id(poi))
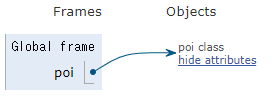
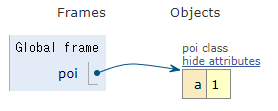
printの実行結果は、以下の通りでした。やっぱり違うモノ(オブジェクト)になってますよね。
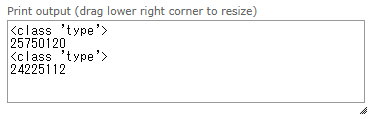
ちょっと意外に感じたのは、class定義されたもののtypeが「type」だったことです。やっぱり、<class ‘class’>はちょっとヘンだよねぇ、ということにでもなったのでしょうか?このあたりの呼び名は宗教観(?)の違いで争われそうですね。
idは予想通り異なっていたので、class定義することで、以前のクラスが別のオブジェクトで上書きされた、という風に考えられますね。あ、、、でも、上書きではありませんでしたね。自分で説明しておいて間違えました。変数名は、オブジェクトに張り付けた付箋のようなイメージです、と説明したのでした。実際にはpoiクラスというクラスのオブジェクトができて、再度、別のpoiクラスというクラスのオブジェクトができる、というのが正しい考え方ですね。ちょっと変数にセットしてみてやってみます。
class poi:
pass
poiA = poi
class poi:
a = 1
poiB = poi
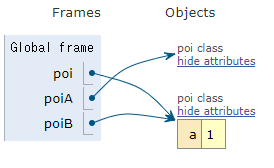
予想通り、「poi class」というオブジェクトが二つできました。先ほどの例ではpoiAに代入しなかったので、最初の「poi class」オブジェクトがガベージコレクトされて捨てられてしまった、ということですね。
