
見に来てくださって、ありがとうございます。石川さんです。
さて、今回は、matplotlibのsubplotとタイトルにありますが、メインはsubplotではありませんね。subplotの出力順を変更したい、というだけの、標準的なプログラミングのお話です。
やりたいこと
通常、subplotを使うと、複数のグラフを並べて出力することができます。こんな具合です。こちらのサイトを参考に出力してみました。
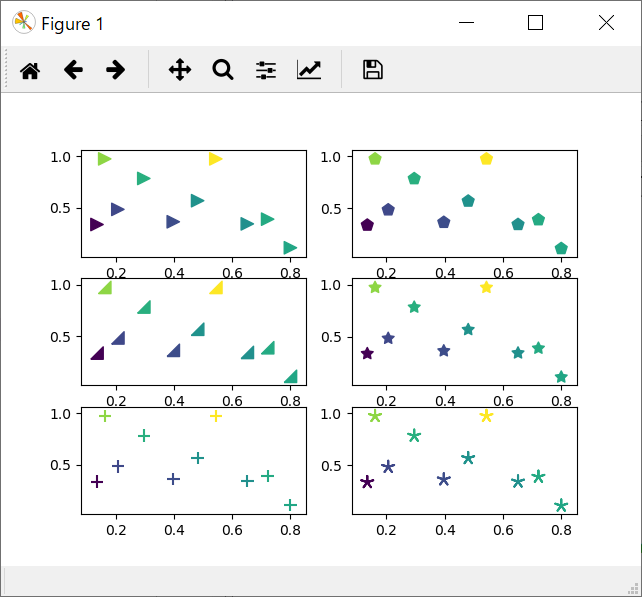
ソースコードは以下の通りです。
import numpy as np
import matplotlib.pyplot as plt
x = np.random.rand(10)
y = np.random.rand(10)
z = np.sqrt(x**2 + y**2)
verts = np.array([[-1, -1], [1, -1], [1, 1], [-1, -1]])
markers = (">", (5, 0), verts, (5, 1), '+', (5, 2))
for i, m in enumerate(markers, 1):
plt.subplot(3, 2, i)
plt.scatter(x, y, s=80, c=z, marker=m)
plt.show()
11行目の、plt.subplot(3, 2, i)でサブプロットを作成しています。最初の二つのパラメータは行列を表しています。今回は、3行2列を表します。iはインデックス値で、1から順番に以下のとおり、左から右、上から下へ、3行2列を以下のような順番で出力していきます。
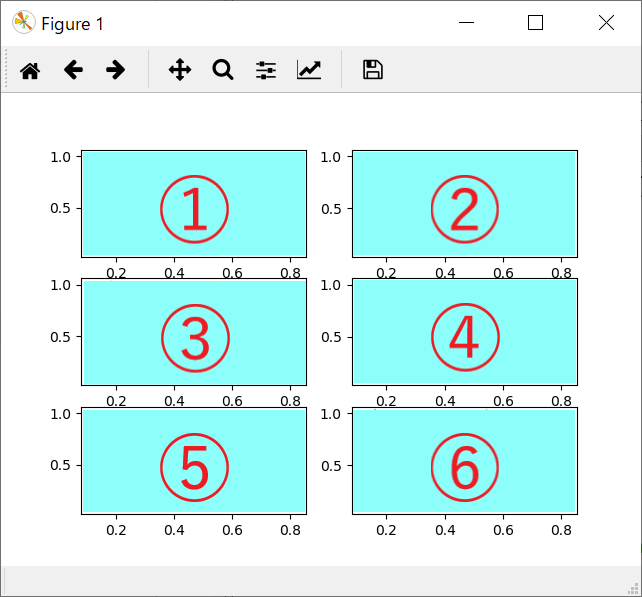
subplotデフォルトの出力順
これを以下のように出力したい、という要望です。
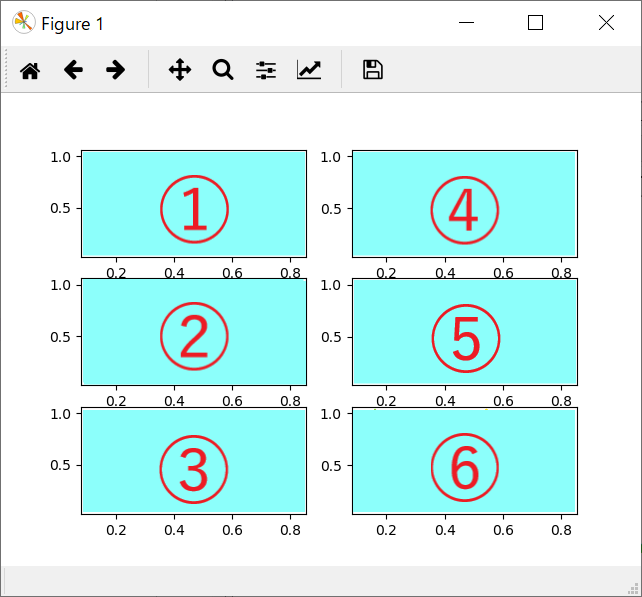
subplotのオプションか何かで簡単に変更できないかと思って調べてみましたが、そのようなオプションは見つけられませんでした。かわりにsubplotsを使って行列の配列を取得する方法があったので、これならば、今回のような工夫は必要なさそうです。ま、でも、今回は頭の体操ですね。もっと簡単な方法があれば、どなたか教えてください。
1~6のループを割り算したり、余りを求めたり、numpy.transpose()が使えるかも、と、検討してみたけど、これは行列が同じ数のときしか使えないとか、いろいろと実験してみました。その結果、今回は、インデックスを[1, 3, 5, 2, 4, 6]というふうに出力すれば望みどおりに出力できることがわかりました。ここまでくればもうできたも同然ですね。コーディングしてみました。
import numpy as np
import matplotlib.pyplot as plt
x = np.random.rand(10)
y = np.random.rand(10)
z = np.sqrt(x**2 + y**2)
verts = np.array([[-1, -1], [1, -1], [1, 1], [-1, -1]])
markers = (">", (5, 0), verts, (5, 1), '+', (5, 2))
def index_generator(row, col):
for c in range(col):
for i in range(c + 1, row * col + 1, col):
yield i
index = index_generator(3, 2)
for i, m in zip(index, markers):
plt.subplot(3, 2, i)
plt.scatter(x, y, s=80, c=z, marker=m)
plt.show()
ポイントは11~14行目、知ったかぶりをして、ジェネレータを作ってみました。パラメータは行、列です。関数内では、列数分繰り返しますが、1から始めて列数ごとに数字を取り出していきます。これにより、3行2列を指定した場合、列の1回目のループで、1、3、5、を戻し、列の2回目のループで、2、4、6を取り出しています。
14行目の「yield i」を使うことで関数がジェネレータになります。ジェネレータは、次の要素が取り出されるまで、値を生成しないのでメモリが節約できる、という特徴があります。
17行目でindexを定義してインデックスの生成にはこちらを利用します。ということで、19行目のforループもenumerateをやめて、zipに変更しました。
まとめ
割り算や余りを使って計算でできるのでは、と、簡単そうに思いましたが、実は、ちょっとひねりが必要だったという、よい問題でした。